── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors4 Transformação de dados
4.1 Tidyverse

O Tidyverse é um conjunto integrado de pacotes projetado para simplificar o processo de manipulação e visualização de dados na linguagem R, sendo especialmente útil em tarefas de análise de dados, ciência de dados e estatística. Ele reúne uma série de pacotes que compartilham uma sintaxe e princípios consistentes, facilitando o aprendizado e a utilização de múltiplos pacotes simultaneamente. Entre os principais componentes do Tidyverse estão pacotes amplamente conhecidos, como dplyr para manipulação eficiente de dados, ggplot2 para visualização gráfica poderosa e flexível, tidyr para organização e transformação de dados, readr para leitura de dados de diferentes formatos, purrr para programação funcional, e tibble, que aprimora o uso de data frames com uma estrutura mais moderna e robusta.
O Tidyverse surge como uma alternativa superior ao uso das funções base do R, oferecendo maior eficiência, rapidez e simplicidade no manuseio de dados, especialmente quando se trabalha com grandes volumes de informação. Sua filosofia de uso está alinhada ao conceito de Tidy Data, que estabelece um padrão para a organização de dados. Segundo essa abordagem, os dados devem ser dispostos de forma clara e consistente, em que cada variável é representada por uma coluna, cada observação por uma linha, e cada tipo de unidade observacional é armazenado em uma tabela separada. Esse formato padronizado facilita a análise e manipulação dos dados, permitindo que os pacotes do Tidyverse funcionem de maneira mais integrada e eficiente, resultando em fluxos de trabalho mais claros e rápidos.
A filosofia do Tidy Data não apenas organiza os dados de maneira lógica, mas também promove práticas que facilitam o uso e a interpretação dos dados ao longo do processo analítico. Isso é especialmente útil em projetos complexos, onde a consistência na estruturação dos dados pode prevenir erros e simplificar etapas subsequentes da análise, como a visualização e modelagem estatística.
O Universo Tidyverse é composto por diversos pacotes principais, e diversos pacotes secundários que apresentam a mesma filosofia de organização e manipulação de dados.
Os pacotes principais do Tidyverse são:
Já os pacotes secundários do Tidyverse são: 
Note que essa lista está incompleta, uma vez que novos pacotes são adicionados regularmente ao Tidyverse, expandindo ainda mais suas funcionalidades e possibilidades de análise de dados.
Além do universo do tidyverse para manipulação de dados, existe todo um universo próprio para modelagem de dados e machine learning. Esse universo é conhecido como tidymodels.
4.1.1 Utilizando o Tidyverse
Para instalar o Tidyverse, basta executar o comando install.packages("tidyverse"). E após sua instação for concluída, basta carregarmos o Tidyverse utilizando o comando library(tidyverse).
4.1.2 Lendo Dados com Tidyverse
Para ler arquivos de texto, é possível utilizar a função readr::read_table(), e para lermos arquivos csv podemos utilizar a função readr::read_csv().
dados <- readr::read_csv("data/Mental Health Dataset.csv")Rows: 292364 Columns: 17
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (17): Timestamp, Gender, Country, Occupation, self_employed, family_hist...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.## Para vermos os dados, podemos utilizar a função head()
head(dados, 2)# A tibble: 2 × 17
Timestamp Gender Country Occupation self_employed family_history treatment
<chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 8/27/2014 11… Female United… Corporate <NA> No Yes
2 8/27/2014 11… Female United… Corporate <NA> Yes Yes
# ℹ 10 more variables: Days_Indoors <chr>, Growing_Stress <chr>,
# Changes_Habits <chr>, Mental_Health_History <chr>, Mood_Swings <chr>,
# Coping_Struggles <chr>, Work_Interest <chr>, Social_Weakness <chr>,
# mental_health_interview <chr>, care_options <chr>dados# A tibble: 292,364 × 17
Timestamp Gender Country Occupation self_employed family_history treatment
<chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 8/27/2014 1… Female United… Corporate <NA> No Yes
2 8/27/2014 1… Female United… Corporate <NA> Yes Yes
3 8/27/2014 1… Female United… Corporate <NA> Yes Yes
4 8/27/2014 1… Female United… Corporate No Yes Yes
5 8/27/2014 1… Female United… Corporate No Yes Yes
6 8/27/2014 1… Female Poland Corporate No No Yes
7 8/27/2014 1… Female Austra… Corporate No Yes Yes
8 8/27/2014 1… Female United… Corporate No No No
9 8/27/2014 1… Female United… Corporate No No No
10 8/27/2014 1… Female United… Corporate No No No
# ℹ 292,354 more rows
# ℹ 10 more variables: Days_Indoors <chr>, Growing_Stress <chr>,
# Changes_Habits <chr>, Mental_Health_History <chr>, Mood_Swings <chr>,
# Coping_Struggles <chr>, Work_Interest <chr>, Social_Weakness <chr>,
# mental_health_interview <chr>, care_options <chr>Outra maneira de visualizarmos os dados é utilizando a função glimpse(), que nos fornece um resumo dos dados, incluindo o número de observações e variáveis, bem como o tipo de dados de cada variável.
## Para vermos o resumo dos dados, podemos utilizar a função glimpse()
glimpse(dados)Rows: 292,364
Columns: 17
$ Timestamp <chr> "8/27/2014 11:29", "8/27/2014 11:31", "8/27/20…
$ Gender <chr> "Female", "Female", "Female", "Female", "Femal…
$ Country <chr> "United States", "United States", "United Stat…
$ Occupation <chr> "Corporate", "Corporate", "Corporate", "Corpor…
$ self_employed <chr> NA, NA, NA, "No", "No", "No", "No", "No", "No"…
$ family_history <chr> "No", "Yes", "Yes", "Yes", "Yes", "No", "Yes",…
$ treatment <chr> "Yes", "Yes", "Yes", "Yes", "Yes", "Yes", "Yes…
$ Days_Indoors <chr> "1-14 days", "1-14 days", "1-14 days", "1-14 d…
$ Growing_Stress <chr> "Yes", "Yes", "Yes", "Yes", "Yes", "Yes", "Yes…
$ Changes_Habits <chr> "No", "No", "No", "No", "No", "No", "No", "No"…
$ Mental_Health_History <chr> "Yes", "Yes", "Yes", "Yes", "Yes", "Yes", "Yes…
$ Mood_Swings <chr> "Medium", "Medium", "Medium", "Medium", "Mediu…
$ Coping_Struggles <chr> "No", "No", "No", "No", "No", "No", "No", "No"…
$ Work_Interest <chr> "No", "No", "No", "No", "No", "No", "No", "No"…
$ Social_Weakness <chr> "Yes", "Yes", "Yes", "Yes", "Yes", "Yes", "Yes…
$ mental_health_interview <chr> "No", "No", "No", "Maybe", "No", "Maybe", "No"…
$ care_options <chr> "Not sure", "No", "Yes", "Yes", "Yes", "Not su…
4.2 Pipes: O operador %>%
![]()
Uma maneira de fazermos os códigos em R mais legíveis é através da utilização dos operadores pipe. Os pipes fazem com a sequência das análises se torne mais aparente, o que torna o código muito menos complexo e mais fácil de ser alterado.
Tomemos como exemplo a seguinte análise: Seja x um vetor com 9 elementos, queremos obter um vetor ordenado do cosseno desses valores. Para fazer isso em R podemos aninhar diversas funções.
x <- c(-4:4)
x[1] -4 -3 -2 -1 0 1 2 3 4[1] 1.0000000 0.5403023 0.5403023 -0.4161468 -0.4161468 -0.6536436 -0.6536436
[8] -0.9899925 -0.9899925O que torna o código pouco legível e difícil de ser interpretado.
Podemos identar o código para faciliar a leitura:
[1] 1.0000000 0.5403023 0.5403023 -0.4161468 -0.4161468 -0.6536436 -0.6536436
[8] -0.9899925 -0.9899925Contudo, ainda assim, o código não é de fácil compreensão, principalmente porque devemos ler o código de dentro para fora. Os pipes surgem como uma alternativa para solucionar esse problema, tornando os códigos mais legíveis e debugáveis. Os pipes, representados pelo operador %>%, são uma característica poderosa e conveniente introduzida pelo pacote magrittr e amplamente adotada em R para simplificar a manipulação de dados. Os pipes permitem encadear sequências de operações em uma maneira legível e intuitiva, tornando o código mais conciso e fácil de entender.
Funcionamento dos Pipes: O operador %>% permite que você passe o resultado de uma expressão como o primeiro argumento de outra expressão. Isso é particularmente útil ao realizar uma série de transformações em um objeto sem a necessidade de criar variáveis intermediárias. O mesmo código que vimos anteriormente, com a utilização de pipe ficaria:
Loading required package: magrittr
Attaching package: 'magrittr'The following object is masked from 'package:purrr':
set_namesThe following object is masked from 'package:tidyr':
extract[1] 1.0000000 0.5403023 0.5403023 -0.4161468 -0.4161468 -0.6536436 -0.6536436
[8] -0.9899925 -0.98999254.2.1 Uso do pipe
-
x %>% fé equivalente àf(x) -
x %>% f(y)é equivalente àf(x, y) -
x %>% f %>% g %>% hé equivalente àh(g(f(x)))
O %>% significa que o elemento à esquerda sera avaliado pela função à direita.
Podemos também utilizar o . como espaço reservado para o elemento à esquerda, isto é:
-
x %>% f(y, .)é equivalente àf(y, x) -
x %>% f(., y)é equivalente àf(x, y) -
x %>% f(y, z = .)é equivalente àf(y, z = x).
4.2.1.1 Exemplos
Note que não conseguimos utilizar o %>% com operadores aritiméticos. Portanto, uma alternativa é utiliarmos as funções add(), subtract(), multiply_by(), raise_to_power(), divide_by() etc. Para a lista completa de funções, utilize ?add.
[1] 2.197622 3.849113 12.793542 5.352542 5.646439 13.575325 7.304581
[8] -1.325306 1.565736 2.771690Outra opção é utilizarmos os a operação entre aspas.
4.2.2 Benefícios dos Pipes
Legibilidade: Os pipes permitem ler o código da esquerda para a direita, refletindo a sequência de operações realizadas.
Redução de Variáveis Intermediárias: Com pipes, não precisamos criar variáveis intermediárias para armazenar resultados parciais.
Encadeamento Simples: O encadeamento de operações se torna mais intuitivo e fácil de seguir o código e procedimentos.
Depuração: Ao usar pipes, podemos isolar cada etapa para depuração, facilitando a identificação de erros.
4.2.3 Pipe de atribuição %<>%
Muitas vezes queremos realizar operações e atribuir os resultados ao mesmo data.frame de entrada, por exemplo, podemos querer criar uma nova variável em meu_data_frame, porem, não temos interesse em duplicar o banco de dados. Podemos fazer uma atribuição explicita ou implicita. Para a explicita, simplismente atribuímos utilizando = ou <-, como vimos até agora durante o curso. Porém, podemos fazer uma atribuição implicita utilizando o operador %<>%.
require(dplyr)
## Atribuição explicita
meu_data_frame <- data.frame(
nome = c("Alice", "Bob", "Carol", "Ana", "João", "Carlos", "Patrícia", "Leonardo"),
idade = c(25, 30, 28, 20, 27, 50, 60, 45),
salario = c(5000, 6000, 5500, 8000, 2000, 3500, 10000, 3800 ),
meio_de_transporte = c('onibus', 'bicicleta', 'onibus', 'carro', 'carro', 'onibus', 'onibus', 'bicicleta'))
meu_data_frame = meu_data_frame %>%
mutate(idade_25 = idade > 25)
glimpse(meu_data_frame)Rows: 8
Columns: 5
$ nome <chr> "Alice", "Bob", "Carol", "Ana", "João", "Carlos", "…
$ idade <dbl> 25, 30, 28, 20, 27, 50, 60, 45
$ salario <dbl> 5000, 6000, 5500, 8000, 2000, 3500, 10000, 3800
$ meio_de_transporte <chr> "onibus", "bicicleta", "onibus", "carro", "carro", …
$ idade_25 <lgl> FALSE, TRUE, TRUE, FALSE, TRUE, TRUE, TRUE, TRUERows: 8
Columns: 6
$ nome <chr> "Alice", "Bob", "Carol", "Ana", "João", "Carlos", "…
$ idade <dbl> 25, 30, 28, 20, 27, 50, 60, 45
$ salario <dbl> 5000, 6000, 5500, 8000, 2000, 3500, 10000, 3800
$ meio_de_transporte <chr> "onibus", "bicicleta", "onibus", "carro", "carro", …
$ idade_25 <lgl> FALSE, TRUE, TRUE, FALSE, TRUE, TRUE, TRUE, TRUE
$ idade_50 <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FAL…4.3 Manipulação de Dados
Loading required package: data.table
Attaching package: 'data.table'The following objects are masked from 'package:lubridate':
hour, isoweek, mday, minute, month, quarter, second, wday, week,
yday, yearThe following objects are masked from 'package:dplyr':
between, first, lastThe following object is masked from 'package:purrr':
transposerequire(dplyr)
require(tidyr)
car_crash = fread("data/Brazil Total highway crashes 2010 - 2023.csv.gz")
# Dados extraídos de https://www.kaggle.com/datasets/liamarguedas/brazil-total-highway-crashes-2010-2023
glimpse(car_crash)Rows: 864,561
Columns: 24
$ data <chr> "01/01/2010", "01/01/2010", "01/01/2010…
$ horario <chr> "04:21:00", "02:13:00", "03:35:00", "07…
$ n_da_ocorrencia <chr> "18", "20", "000024/2010", "000038/2010…
$ tipo_de_ocorrencia <chr> "sem vítima", "sem vítima", "sem vítima…
$ km <chr> "167", "269,5", "77", "52", "33", "24",…
$ trecho <chr> "BR-393/RJ", "BR-116/PR", "BR-290/RS", …
$ sentido <chr> "Norte", "Sul", "Norte", "Norte", "Nort…
$ lugar_acidente <chr> "Rodovia do Aço", "Autopista Regis Bitt…
$ tipo_de_acidente <chr> "Derrapagem", "Colisão Traseira", "COLI…
$ automovel <int> 1, 2, 2, 0, 0, 1, 1, 1, 2, 1, NA, 1, 1,…
$ bicicleta <int> NA, NA, 0, 0, 0, 0, NA, NA, NA, NA, NA,…
$ caminhao <int> NA, NA, 0, 0, 0, 0, NA, NA, NA, NA, NA,…
$ moto <int> NA, NA, 0, 1, 1, 0, NA, NA, NA, NA, 1, …
$ onibus <int> NA, NA, 0, 0, 0, 0, NA, NA, NA, NA, NA,…
$ outros <int> NA, NA, 0, 0, 0, 0, NA, NA, NA, NA, NA,…
$ tracao_animal <int> NA, NA, 0, 0, 0, 0, NA, NA, NA, NA, NA,…
$ transporte_de_cargas_especiais <int> NA, NA, 0, 0, 0, 0, NA, NA, NA, NA, NA,…
$ trator_maquinas <int> NA, NA, 0, 0, 0, 0, NA, NA, NA, NA, NA,…
$ utilitarios <int> NA, NA, 0, 0, 0, 0, NA, NA, NA, NA, NA,…
$ ilesos <int> 1, 3, 2, 1, 1, 1, 3, 4, 4, 1, 0, 1, 1, …
$ levemente_feridos <int> 0, NA, 0, 0, 0, 0, NA, NA, 5, NA, 2, NA…
$ moderadamente_feridos <int> 0, NA, 0, 0, 0, 0, NA, NA, NA, NA, NA, …
$ gravemente_feridos <int> 0, NA, 0, 0, 0, 0, NA, NA, NA, NA, NA, …
$ mortos <int> 0, NA, 0, 0, 0, 0, NA, NA, NA, NA, NA, …4.3.1 Seleção de Variáveis
No tidyverse, a função select() do pacote dplyr é amplamente utilizada para selecionar as colunas relevantes de um conjunto de dados. Além de selecionar colunas pelo nome, a função select() oferece diversas opções avançadas para facilitar a seleção e manipulação de colunas. Vamos explorar algumas dessas opções:
4.3.1.1 Seleção por Nome de Coluna
A forma mais simples de usar o select() é especificar os nomes das colunas que você deseja manter no resultado, por exemplo, podemos estar interessados em selecionarmos a data e o tipo_de_acidente.
data tipo_de_acidente
<char> <char>
1: 01/01/2010 Derrapagem
2: 01/01/2010 Colisão Traseira
3: 01/01/2010 COLISÃO LATERAL
4: 01/01/2010 QUEDA DE MOTO
5: 01/01/2010 QUEDA DE MOTO
6: 01/01/2010 SAÍDA DE PISTA- Seleção por Nome de Coluna que inicie com alguma palavra -
starts_with(): Essa função permite selecionar colunas cujos nomes começam com um determinado padrão de caracteres. No nosso banco de dados, podemos estar interessados em selecionar todas as variáveis que iniciem com “tipo”.
car_crash %>%
select(starts_with("tipo")) %>%
head() tipo_de_ocorrencia tipo_de_acidente
<char> <char>
1: sem vítima Derrapagem
2: sem vítima Colisão Traseira
3: sem vítima COLISÃO LATERAL
4: sem vítima QUEDA DE MOTO
5: sem vítima QUEDA DE MOTO
6: sem vítima SAÍDA DE PISTA- Seleção por Nome de Coluna que termine com alguma palavra -
ends_with(): Essa função permite selecionar colunas cujos nomes terminam com um determinado padrão de caracteres. No nosso banco de dados, podemos estar interessados em selecionar todas as variáveis que terminem com “feridos”.
levemente_feridos moderadamente_feridos gravemente_feridos
<int> <int> <int>
1: 0 0 0
2: NA NA NA
3: 0 0 0
4: 0 0 0
5: 0 0 0
6: 0 0 0- Seleção por Nome de Coluna que contenha alguma palavra -
contains(): Essa função permite selecionar colunas cujos nomes contenham um determinado padrão de caracteres. No nosso banco de dados, podemos estar interessados em selecionar todas as variáveis que contenham “mente”.
4.3.1.2 Seleção de variáveis por Tipos específicos de dados
Muitas vezes, estamos interessados em selecionar apenas variáveis de um tipo, para tratarmos os dados da maneira mais adequada.
- Selecionar apenas variáveis numéricas:
is.numeric()
Rows: 864,561
Columns: 15
$ automovel <int> 1, 2, 2, 0, 0, 1, 1, 1, 2, 1, NA, 1, 1,…
$ bicicleta <int> NA, NA, 0, 0, 0, 0, NA, NA, NA, NA, NA,…
$ caminhao <int> NA, NA, 0, 0, 0, 0, NA, NA, NA, NA, NA,…
$ moto <int> NA, NA, 0, 1, 1, 0, NA, NA, NA, NA, 1, …
$ onibus <int> NA, NA, 0, 0, 0, 0, NA, NA, NA, NA, NA,…
$ outros <int> NA, NA, 0, 0, 0, 0, NA, NA, NA, NA, NA,…
$ tracao_animal <int> NA, NA, 0, 0, 0, 0, NA, NA, NA, NA, NA,…
$ transporte_de_cargas_especiais <int> NA, NA, 0, 0, 0, 0, NA, NA, NA, NA, NA,…
$ trator_maquinas <int> NA, NA, 0, 0, 0, 0, NA, NA, NA, NA, NA,…
$ utilitarios <int> NA, NA, 0, 0, 0, 0, NA, NA, NA, NA, NA,…
$ ilesos <int> 1, 3, 2, 1, 1, 1, 3, 4, 4, 1, 0, 1, 1, …
$ levemente_feridos <int> 0, NA, 0, 0, 0, 0, NA, NA, 5, NA, 2, NA…
$ moderadamente_feridos <int> 0, NA, 0, 0, 0, 0, NA, NA, NA, NA, NA, …
$ gravemente_feridos <int> 0, NA, 0, 0, 0, 0, NA, NA, NA, NA, NA, …
$ mortos <int> 0, NA, 0, 0, 0, 0, NA, NA, NA, NA, NA, …- Selecionar apenas variáveis characters:
is.character()
Rows: 864,561
Columns: 9
$ data <chr> "01/01/2010", "01/01/2010", "01/01/2010", "01/01/20…
$ horario <chr> "04:21:00", "02:13:00", "03:35:00", "07:31:00", "04…
$ n_da_ocorrencia <chr> "18", "20", "000024/2010", "000038/2010", "000027/2…
$ tipo_de_ocorrencia <chr> "sem vítima", "sem vítima", "sem vítima", "sem víti…
$ km <chr> "167", "269,5", "77", "52", "33", "24", "52", "40",…
$ trecho <chr> "BR-393/RJ", "BR-116/PR", "BR-290/RS", "BR-116/RS",…
$ sentido <chr> "Norte", "Sul", "Norte", "Norte", "Norte", "Sul", "…
$ lugar_acidente <chr> "Rodovia do Aço", "Autopista Regis Bittencourt", "C…
$ tipo_de_acidente <chr> "Derrapagem", "Colisão Traseira", "COLISÃO LATERAL"…- Selecionar apenas variáveis lógicas:
is.logical()
4.3.1.3 Seleção por critérios
-
all_of(),any_of(): Permitem usar variáveis definidas externamente como argumentos da função. Note que quando utilizamosall_of()todas as variáveis devem existir, jáany_of()permite que nem todas as variáveis existam no banco de dados.
vars_interesse = c("automovel", "bicicleta", "onibus")
car_crash %>%
select(all_of(vars_interesse)) %>%
glimpse()Rows: 864,561
Columns: 3
$ automovel <int> 1, 2, 2, 0, 0, 1, 1, 1, 2, 1, NA, 1, 1, 2, 2, 1, 1, NA, 1, 2…
$ bicicleta <int> NA, NA, 0, 0, 0, 0, NA, NA, NA, NA, NA, NA, 0, NA, NA, NA, N…
$ onibus <int> NA, NA, 0, 0, 0, 0, NA, NA, NA, NA, NA, NA, 0, NA, NA, NA, N…vars_interesse2 = c("automovel", "bicicleta", "onibus", "trator")
car_crash %>%
select(any_of(vars_interesse2)) %>%
glimpse()Rows: 864,561
Columns: 3
$ automovel <int> 1, 2, 2, 0, 0, 1, 1, 1, 2, 1, NA, 1, 1, 2, 2, 1, 1, NA, 1, 2…
$ bicicleta <int> NA, NA, 0, 0, 0, 0, NA, NA, NA, NA, NA, NA, 0, NA, NA, NA, N…
$ onibus <int> NA, NA, 0, 0, 0, 0, NA, NA, NA, NA, NA, NA, 0, NA, NA, NA, N…4.3.2 Seleção de Observações
No pacote dplyr do tidyverse, a função filter() é amplamente utilizada para filtrar linhas de um conjunto de dados com base em condições específicas. Ela oferece diversas opções para criar filtros complexos que atendam às suas necessidades de análise. Vamos explorar diferentes tipos de filtros e como utilizá-los de maneira eficaz.
4.3.2.1 Filtros Simples
Filtros simples envolvem comparações entre valores de uma coluna e um valor constante. Alguns operadores de comparação comuns incluem:
==: Igual a!=: Diferente de<: Menor que>: Maior que<=: Menor ou igual a>=: Maior ou igual a
Podemos estar interessados em filtrar as observações com pelo menos três carros envolvidos no acidente:
Rows: 34,388
Columns: 24
$ data <chr> "01/01/2010", "01/01/2011", "01/01/2011…
$ horario <chr> "13:14:00", "23:21:00", "12:21:00", "13…
$ n_da_ocorrencia <chr> "150", "542", "212", "135", "309", "145…
$ tipo_de_ocorrencia <chr> "sem vítima", "sem vítima", "sem vítima…
$ km <chr> "560", "137,5", "68,8", "269", "193", "…
$ trecho <chr> "BR-116/PR", "BR-101/SC", "BR-116/SP", …
$ sentido <chr> "Sul", "Norte", "Pista Sul", "Norte", "…
$ lugar_acidente <chr> "Autopista Regis Bittencourt", "Autopis…
$ tipo_de_acidente <chr> "Colisão Traseira", "Colisão Traseira",…
$ automovel <int> 3, 3, 3, 4, 3, 3, 3, 4, 3, 3, 3, 6, 3, …
$ bicicleta <int> NA, NA, 0, NA, NA, NA, NA, NA, NA, NA, …
$ caminhao <int> NA, NA, 0, NA, NA, NA, NA, 1, NA, NA, N…
$ moto <int> NA, NA, 0, NA, NA, NA, NA, NA, NA, NA, …
$ onibus <int> NA, NA, 0, NA, NA, NA, NA, NA, NA, NA, …
$ outros <int> NA, NA, 0, NA, NA, NA, NA, 1, NA, NA, N…
$ tracao_animal <int> NA, NA, 0, NA, NA, NA, NA, NA, NA, NA, …
$ transporte_de_cargas_especiais <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ trator_maquinas <int> NA, NA, 0, NA, NA, NA, NA, NA, NA, NA, …
$ utilitarios <int> NA, NA, 0, NA, NA, NA, NA, 1, NA, NA, N…
$ ilesos <int> 14, 3, 11, 7, 3, 3, 3, 7, 3, 9, 8, 6, 3…
$ levemente_feridos <int> NA, NA, 0, NA, NA, NA, NA, 3, NA, 2, NA…
$ moderadamente_feridos <int> NA, NA, 0, NA, NA, NA, NA, NA, NA, NA, …
$ gravemente_feridos <int> NA, NA, 0, NA, NA, NA, NA, 1, NA, NA, N…
$ mortos <int> NA, NA, 0, NA, NA, NA, NA, NA, NA, NA, …4.3.2.2 Filtros Combinados
Você pode combinar filtros usando os operadores lógicos & (AND) e | (OR) para criar condições mais complexas.
Podemos estar interessados em filtrar as observações com pelo menos três carros e dois caminhões envolvidos no acidente:
dados_filtrados <- car_crash %>%
filter(automovel >= 3 & caminhao > 2)
dados_filtrados %>%
glimpse()Rows: 177
Columns: 24
$ data <chr> "01/02/2018", "01/03/2012", "01/03/2019…
$ horario <chr> "07:45:00", "09:04:00", "00:07:00", "08…
$ n_da_ocorrencia <chr> "119", "163", "2", "223", "238", "457",…
$ tipo_de_ocorrencia <chr> "sem vítima", "com vítima", "sem vítima…
$ km <chr> "41,941", "111,19999694824219", "667,5"…
$ trecho <chr> "BR-101/SC", "BR-116/PR", "BR-376/PR", …
$ sentido <chr> "Norte", "Sul", "Sul", "Pista Norte", "…
$ lugar_acidente <chr> "Autopista Litoral Sul", "Autopista Lit…
$ tipo_de_acidente <chr> "Engavetamento", "Colisão Traseira", "E…
$ automovel <int> 3, 3, 8, 3, 4, 3, 4, 3, 3, 8, 7, 5, 4, …
$ bicicleta <int> NA, NA, NA, 0, NA, NA, NA, NA, NA, NA, …
$ caminhao <int> 3, 3, 4, 3, 4, 3, 3, 4, 3, 3, 3, 3, 3, …
$ moto <int> NA, 1, NA, 0, NA, NA, NA, NA, NA, NA, N…
$ onibus <int> NA, NA, NA, 0, NA, NA, NA, NA, NA, NA, …
$ outros <int> NA, NA, NA, 0, NA, NA, NA, NA, NA, NA, …
$ tracao_animal <int> NA, NA, NA, 0, NA, NA, NA, NA, NA, NA, …
$ transporte_de_cargas_especiais <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ trator_maquinas <int> NA, NA, NA, 0, NA, NA, NA, NA, NA, NA, …
$ utilitarios <int> 1, NA, NA, 0, NA, NA, NA, 1, NA, NA, NA…
$ ilesos <int> 7, 6, 29, 8, 3, 4, 7, 9, 11, 50, 8, 11,…
$ levemente_feridos <int> NA, 1, NA, 0, NA, NA, NA, NA, NA, NA, 5…
$ moderadamente_feridos <int> NA, NA, NA, 0, 2, NA, 2, 1, NA, 1, NA, …
$ gravemente_feridos <int> NA, NA, NA, 0, 3, NA, NA, NA, NA, NA, N…
$ mortos <int> NA, NA, NA, 0, 5, 3, NA, NA, NA, NA, NA…Podemos omitir o operador lógico &, então a função ficaria:
Rows: 177
Columns: 24
$ data <chr> "01/02/2018", "01/03/2012", "01/03/2019…
$ horario <chr> "07:45:00", "09:04:00", "00:07:00", "08…
$ n_da_ocorrencia <chr> "119", "163", "2", "223", "238", "457",…
$ tipo_de_ocorrencia <chr> "sem vítima", "com vítima", "sem vítima…
$ km <chr> "41,941", "111,19999694824219", "667,5"…
$ trecho <chr> "BR-101/SC", "BR-116/PR", "BR-376/PR", …
$ sentido <chr> "Norte", "Sul", "Sul", "Pista Norte", "…
$ lugar_acidente <chr> "Autopista Litoral Sul", "Autopista Lit…
$ tipo_de_acidente <chr> "Engavetamento", "Colisão Traseira", "E…
$ automovel <int> 3, 3, 8, 3, 4, 3, 4, 3, 3, 8, 7, 5, 4, …
$ bicicleta <int> NA, NA, NA, 0, NA, NA, NA, NA, NA, NA, …
$ caminhao <int> 3, 3, 4, 3, 4, 3, 3, 4, 3, 3, 3, 3, 3, …
$ moto <int> NA, 1, NA, 0, NA, NA, NA, NA, NA, NA, N…
$ onibus <int> NA, NA, NA, 0, NA, NA, NA, NA, NA, NA, …
$ outros <int> NA, NA, NA, 0, NA, NA, NA, NA, NA, NA, …
$ tracao_animal <int> NA, NA, NA, 0, NA, NA, NA, NA, NA, NA, …
$ transporte_de_cargas_especiais <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ trator_maquinas <int> NA, NA, NA, 0, NA, NA, NA, NA, NA, NA, …
$ utilitarios <int> 1, NA, NA, 0, NA, NA, NA, 1, NA, NA, NA…
$ ilesos <int> 7, 6, 29, 8, 3, 4, 7, 9, 11, 50, 8, 11,…
$ levemente_feridos <int> NA, 1, NA, 0, NA, NA, NA, NA, NA, NA, 5…
$ moderadamente_feridos <int> NA, NA, NA, 0, 2, NA, 2, 1, NA, 1, NA, …
$ gravemente_feridos <int> NA, NA, NA, 0, 3, NA, NA, NA, NA, NA, N…
$ mortos <int> NA, NA, NA, 0, 5, 3, NA, NA, NA, NA, NA…Podemos estar interessados em filtrar as observações com pelo menos três carros OU dois caminhões envolvidos no acidente:
dados_filtrados <- car_crash %>%
filter(automovel >= 3 | caminhao > 2)
dados_filtrados %>%
glimpse()Rows: 39,208
Columns: 24
$ data <chr> "01/01/2010", "01/01/2011", "01/01/2011…
$ horario <chr> "13:14:00", "23:21:00", "12:21:00", "13…
$ n_da_ocorrencia <chr> "150", "542", "212", "135", "309", "145…
$ tipo_de_ocorrencia <chr> "sem vítima", "sem vítima", "sem vítima…
$ km <chr> "560", "137,5", "68,8", "269", "193", "…
$ trecho <chr> "BR-116/PR", "BR-101/SC", "BR-116/SP", …
$ sentido <chr> "Sul", "Norte", "Pista Sul", "Norte", "…
$ lugar_acidente <chr> "Autopista Regis Bittencourt", "Autopis…
$ tipo_de_acidente <chr> "Colisão Traseira", "Colisão Traseira",…
$ automovel <int> 3, 3, 3, 4, 3, 3, 3, 4, 3, 3, 3, 6, 3, …
$ bicicleta <int> NA, NA, 0, NA, NA, NA, NA, NA, NA, NA, …
$ caminhao <int> NA, NA, 0, NA, NA, NA, NA, 1, NA, NA, N…
$ moto <int> NA, NA, 0, NA, NA, NA, NA, NA, NA, NA, …
$ onibus <int> NA, NA, 0, NA, NA, NA, NA, NA, NA, NA, …
$ outros <int> NA, NA, 0, NA, NA, NA, NA, 1, NA, NA, N…
$ tracao_animal <int> NA, NA, 0, NA, NA, NA, NA, NA, NA, NA, …
$ transporte_de_cargas_especiais <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ trator_maquinas <int> NA, NA, 0, NA, NA, NA, NA, NA, NA, NA, …
$ utilitarios <int> NA, NA, 0, NA, NA, NA, NA, 1, NA, NA, N…
$ ilesos <int> 14, 3, 11, 7, 3, 3, 3, 7, 3, 9, 8, 6, 3…
$ levemente_feridos <int> NA, NA, 0, NA, NA, NA, NA, 3, NA, 2, NA…
$ moderadamente_feridos <int> NA, NA, 0, NA, NA, NA, NA, NA, NA, NA, …
$ gravemente_feridos <int> NA, NA, 0, NA, NA, NA, NA, 1, NA, NA, N…
$ mortos <int> NA, NA, 0, NA, NA, NA, NA, NA, NA, NA, …4.3.2.3 Filtrando valores dentro de um intervalo
Para filtramos valores dentro de um intervalo definido podemos utilizar as funções between() e %in%.
A função between() é útil para filtrar valores dentro de um intervalo numérico.
Podemos estar interessados em filtrar as observações com valores entre 4 e 8 motos envolvidas no acidente:
dados_filtrados <- car_crash %>%
filter(between(moto, lower = 4, upper = 8, incbounds = TRUE))
dados_filtrados %>%
glimpse()Rows: 32
Columns: 24
$ data <chr> "02/02/2012", "02/08/2022", "04/02/2021…
$ horario <chr> "09:07:00", "14:34:00", "06:24:00", "07…
$ n_da_ocorrencia <chr> "35", "333", "111", "118", "35", "70", …
$ tipo_de_ocorrencia <chr> "sem vítima", "Acidente com Danos Mater…
$ km <chr> "59,7", "506,000", "510,3", "96,99", "5…
$ trecho <chr> "BR-153/SP", "BR-153/GO", "BR-040/MG", …
$ sentido <chr> "Norte", "Sul", "Sul", "Sul", "Sul", "S…
$ lugar_acidente <chr> "Transbrasiliana", "Concebra", "VIA040"…
$ tipo_de_acidente <chr> "Choque contra objeto na faixa de rolam…
$ automovel <int> NA, 0, 0, 0, 0, 4, 1, 1, 1, 0, NA, 1, 2…
$ bicicleta <int> NA, 0, 0, 0, 0, 0, NA, 0, NA, 0, NA, NA…
$ caminhao <int> 1, 0, 0, 0, 0, 0, NA, 0, NA, 0, NA, 0, …
$ moto <int> 4, 4, 5, 4, 4, 4, 4, 4, 4, 4, 4, 5, 4, …
$ onibus <int> NA, 0, 0, 0, 0, 0, NA, 0, NA, 0, NA, 0,…
$ outros <int> NA, 0, 1, 0, 1, 0, NA, 0, NA, 0, NA, 0,…
$ tracao_animal <int> NA, 0, 0, 0, 0, 0, NA, 0, NA, 0, NA, 0,…
$ transporte_de_cargas_especiais <int> NA, 0, 0, 0, 0, 0, NA, 0, NA, 0, NA, NA…
$ trator_maquinas <int> NA, 0, 0, 0, 0, 0, NA, 0, NA, 0, NA, NA…
$ utilitarios <int> NA, 0, 0, 0, 0, 0, NA, 0, NA, 0, NA, NA…
$ ilesos <int> 5, 4, 3, 1, 0, 0, 1, 1, 6, 2, 4, 2, 5, …
$ levemente_feridos <int> NA, 0, 0, 0, 0, 1, 2, 4, NA, 1, 1, 0, 0…
$ moderadamente_feridos <int> NA, 0, 0, 1, 0, 0, NA, 0, NA, 0, NA, 0,…
$ gravemente_feridos <int> NA, 0, 0, 0, 0, 0, 1, 0, NA, 0, NA, 1, …
$ mortos <int> NA, 0, 0, 0, 0, 0, 1, 0, NA, 0, NA, 0, …A função %in% é usada para filtrar valores que correspondem a um conjunto de valores.
Podemos estar interessados em filtrar as observações com ocorrência em alguma das seguintes operadoras: “Autopista Regis Bittencourt”, “Autopista Litoral Sul”, “Via Sul”.
autopistas = c("Autopista Regis Bittencourt", "Autopista Litoral Sul", "Via Sul")
dados_filtrados <- car_crash %>%
filter(lugar_acidente %in% autopistas)
dados_filtrados %>%
glimpse()Rows: 203,036
Columns: 24
$ data <chr> "01/01/2010", "01/01/2010", "01/01/2010…
$ horario <chr> "02:13:00", "11:20:00", "18:07:00", "15…
$ n_da_ocorrencia <chr> "20", "125", "214", "354", "377", "142"…
$ tipo_de_ocorrencia <chr> "sem vítima", "sem vítima", "sem vítima…
$ km <chr> "269,5", "52", "40", "132", "35", "273"…
$ trecho <chr> "BR-116/PR", "BR-116/PR", "BR-116/PR", …
$ sentido <chr> "Sul", "Norte", "Sul", "Sul", "Sul", "N…
$ lugar_acidente <chr> "Autopista Regis Bittencourt", "Autopis…
$ tipo_de_acidente <chr> "Colisão Traseira", "Saida de Pista", "…
$ automovel <int> 2, 1, 1, 1, NA, NA, 1, 1, 1, 1, NA, 1, …
$ bicicleta <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ caminhao <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ moto <int> NA, NA, NA, NA, 1, 1, NA, NA, NA, NA, N…
$ onibus <int> NA, NA, NA, NA, NA, 1, NA, NA, NA, NA, …
$ outros <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ tracao_animal <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ transporte_de_cargas_especiais <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ trator_maquinas <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ utilitarios <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ ilesos <int> 3, 3, 4, 1, 0, 2, 0, 1, 3, 2, 4, 1, 4, …
$ levemente_feridos <int> NA, NA, NA, NA, 2, NA, NA, NA, NA, 1, N…
$ moderadamente_feridos <int> NA, NA, NA, NA, NA, 1, NA, NA, NA, NA, …
$ gravemente_feridos <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ mortos <int> NA, NA, NA, NA, NA, NA, 2, NA, NA, NA, …Podemos estar interessados nas autopistas que não são operadas pelas mesmas operadoras. Para isso precisamos definir um operador de not in.
`%ni%` <- Negate(`%in%`)
dados_filtrados <- car_crash %>%
filter(lugar_acidente %ni% autopistas)
dados_filtrados %>%
glimpse()Rows: 661,525
Columns: 24
$ data <chr> "01/01/2010", "01/01/2010", "01/01/2010…
$ horario <chr> "04:21:00", "03:35:00", "07:31:00", "04…
$ n_da_ocorrencia <chr> "18", "000024/2010", "000038/2010", "00…
$ tipo_de_ocorrencia <chr> "sem vítima", "sem vítima", "sem vítima…
$ km <chr> "167", "77", "52", "33", "24", "119,5",…
$ trecho <chr> "BR-393/RJ", "BR-290/RS", "BR-116/RS", …
$ sentido <chr> "Norte", "Norte", "Norte", "Norte", "Su…
$ lugar_acidente <chr> "Rodovia do Aço", "Concepa", "Concepa",…
$ tipo_de_acidente <chr> "Derrapagem", "COLISÃO LATERAL", "QUEDA…
$ automovel <int> 1, 2, 0, 0, 1, 2, 1, 1, 2, 2, 1, 1, NA,…
$ bicicleta <int> NA, 0, 0, 0, 0, NA, NA, 0, NA, NA, NA, …
$ caminhao <int> NA, 0, 0, 0, 0, NA, NA, 0, NA, NA, NA, …
$ moto <int> NA, 0, 1, 1, 0, NA, NA, 0, NA, NA, NA, …
$ onibus <int> NA, 0, 0, 0, 0, NA, NA, 0, NA, NA, NA, …
$ outros <int> NA, 0, 0, 0, 0, NA, NA, 0, NA, NA, NA, …
$ tracao_animal <int> NA, 0, 0, 0, 0, NA, NA, 0, NA, NA, NA, …
$ transporte_de_cargas_especiais <int> NA, 0, 0, 0, 0, NA, NA, NA, NA, NA, NA,…
$ trator_maquinas <int> NA, 0, 0, 0, 0, NA, NA, 0, NA, NA, NA, …
$ utilitarios <int> NA, 0, 0, 0, 0, NA, NA, 0, NA, NA, NA, …
$ ilesos <int> 1, 2, 1, 1, 1, 4, 1, 1, 2, 2, 0, 1, 0, …
$ levemente_feridos <int> 0, 0, 0, 0, 0, 5, NA, 0, NA, NA, 2, NA,…
$ moderadamente_feridos <int> 0, 0, 0, 0, 0, NA, NA, 0, NA, NA, NA, N…
$ gravemente_feridos <int> 0, 0, 0, 0, 0, NA, NA, 0, NA, NA, NA, N…
$ mortos <int> 0, 0, 0, 0, 0, NA, NA, 0, NA, NA, NA, N…Alternativamente,
Rows: 661,525
Columns: 24
$ data <chr> "01/01/2010", "01/01/2010", "01/01/2010…
$ horario <chr> "04:21:00", "03:35:00", "07:31:00", "04…
$ n_da_ocorrencia <chr> "18", "000024/2010", "000038/2010", "00…
$ tipo_de_ocorrencia <chr> "sem vítima", "sem vítima", "sem vítima…
$ km <chr> "167", "77", "52", "33", "24", "119,5",…
$ trecho <chr> "BR-393/RJ", "BR-290/RS", "BR-116/RS", …
$ sentido <chr> "Norte", "Norte", "Norte", "Norte", "Su…
$ lugar_acidente <chr> "Rodovia do Aço", "Concepa", "Concepa",…
$ tipo_de_acidente <chr> "Derrapagem", "COLISÃO LATERAL", "QUEDA…
$ automovel <int> 1, 2, 0, 0, 1, 2, 1, 1, 2, 2, 1, 1, NA,…
$ bicicleta <int> NA, 0, 0, 0, 0, NA, NA, 0, NA, NA, NA, …
$ caminhao <int> NA, 0, 0, 0, 0, NA, NA, 0, NA, NA, NA, …
$ moto <int> NA, 0, 1, 1, 0, NA, NA, 0, NA, NA, NA, …
$ onibus <int> NA, 0, 0, 0, 0, NA, NA, 0, NA, NA, NA, …
$ outros <int> NA, 0, 0, 0, 0, NA, NA, 0, NA, NA, NA, …
$ tracao_animal <int> NA, 0, 0, 0, 0, NA, NA, 0, NA, NA, NA, …
$ transporte_de_cargas_especiais <int> NA, 0, 0, 0, 0, NA, NA, NA, NA, NA, NA,…
$ trator_maquinas <int> NA, 0, 0, 0, 0, NA, NA, 0, NA, NA, NA, …
$ utilitarios <int> NA, 0, 0, 0, 0, NA, NA, 0, NA, NA, NA, …
$ ilesos <int> 1, 2, 1, 1, 1, 4, 1, 1, 2, 2, 0, 1, 0, …
$ levemente_feridos <int> 0, 0, 0, 0, 0, 5, NA, 0, NA, NA, 2, NA,…
$ moderadamente_feridos <int> 0, 0, 0, 0, 0, NA, NA, 0, NA, NA, NA, N…
$ gravemente_feridos <int> 0, 0, 0, 0, 0, NA, NA, 0, NA, NA, NA, N…
$ mortos <int> 0, 0, 0, 0, 0, NA, NA, 0, NA, NA, NA, N…Outras vezes, podemos utilizar o operador %like% que busca padrões. Por exemplo, podemos estar interessados em buscar todos acidentes que ocorreram com vítimas, e no campo tipo_de_ocorrencia podemos simplesmente buscar por:
Rows: 219,213
Columns: 24
$ data <chr> "01/01/2010", "01/01/2010", "01/01/2010…
$ horario <chr> "15:53:00", "16:30:00", "01:06:00", "11…
$ n_da_ocorrencia <chr> "48", "377", "2", "102", "142", "39", "…
$ tipo_de_ocorrencia <chr> "com vítima", "com vítima", "com vítima…
$ km <chr> "119,5", "35", "114", "64", "273", "316…
$ trecho <chr> "BR-116/PR", "BR-101/SC", "BR-040/RJ", …
$ sentido <chr> "Sul", "Sul", "Sul", "Sul", "Norte", "N…
$ lugar_acidente <chr> "Autopista Planalto Sul", "Autopista Li…
$ tipo_de_acidente <chr> "Colisão Transversal", "Queda de Moto",…
$ automovel <int> 2, NA, 1, 1, NA, 1, 1, 1, 1, 1, 1, 1, 1…
$ bicicleta <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ caminhao <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ moto <int> NA, 1, NA, NA, 1, NA, NA, NA, NA, NA, N…
$ onibus <int> NA, NA, NA, NA, 1, NA, NA, NA, NA, NA, …
$ outros <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ tracao_animal <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ transporte_de_cargas_especiais <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ trator_maquinas <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ utilitarios <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ ilesos <int> 4, 0, 0, 0, 2, 0, 0, 1, 1, 2, 4, 1, 2, …
$ levemente_feridos <int> 5, 2, 2, 1, NA, NA, 1, 3, 1, 1, 2, 2, 2…
$ moderadamente_feridos <int> NA, NA, NA, NA, 1, NA, NA, NA, NA, NA, …
$ gravemente_feridos <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ mortos <int> NA, NA, NA, NA, NA, 2, NA, NA, NA, NA, …Algumas vezes temos apenas vários padrões de texto que gostaríamos de buscar. Para isso, a função grepl() permite filtrar com base em padrões de texto.
Rows: 2,005
Columns: 24
$ data <chr> "01/01/2021", "01/01/2021", "01/01/2023…
$ horario <chr> "04:46:54", "14:00:09", "12:34:00", "16…
$ n_da_ocorrencia <chr> "23", "83", "58", "90", "95", "121", "1…
$ tipo_de_ocorrencia <chr> "ac03 - Acidente com vítima ilesa", "ac…
$ km <chr> "163,2", "37,8", "17,781", "42", "109",…
$ trecho <chr> "BR-050/GO", "BR-050/MG", "BR-116/RJ", …
$ sentido <chr> "Norte", "Sul", "Sul", "Sul", "Norte", …
$ lugar_acidente <chr> "ECO050", "ECO050", "Ecoriominas", "Eco…
$ tipo_de_acidente <chr> "Atropelamento de Animal", "Choque - De…
$ automovel <int> 1, 1, NA, 2, 1, NA, NA, 1, 1, NA, 1, 1,…
$ bicicleta <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ caminhao <int> NA, NA, 1, NA, NA, NA, NA, NA, NA, 1, N…
$ moto <int> NA, NA, NA, NA, NA, 1, NA, NA, NA, NA, …
$ onibus <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ outros <int> NA, NA, NA, NA, 1, NA, NA, NA, NA, NA, …
$ tracao_animal <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ transporte_de_cargas_especiais <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ trator_maquinas <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ utilitarios <int> NA, NA, NA, NA, NA, NA, 1, NA, NA, NA, …
$ ilesos <int> 1, 2, 1, 4, 2, 2, 1, 1, 1, 1, 1, 7, 5, …
$ levemente_feridos <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ moderadamente_feridos <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ gravemente_feridos <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ mortos <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…4.4 Exercícios
- Utilizando o banco de dados
car_crash, faça o que se pede:
- Selecione as variáveis
data,tipo_de_ocorrencia,automovel,bicicleta,onibus,caminhao,moto,trator,outrosetotal. - Selecione todas as variáveis que contenham a palavra
feridos. - Selecione todas as variáveis numéricas.
- Selecione todas as variáveis lógicas.
- Selecione todas as variáveis que terminem com a letra
o. - Selecione todas as variáveis que iniciem com a letra
t. - Filtre as observações com pelo menos 5 carros E 3 motos envolvidos no acidente.
- Filtre as observações com pelo menos 5 carros OU 3 motos envolvidos no acidente.
- Filtre as observações com vítimas.
- Filtre as observações com pelo menos 5 carros OU 3 motos envolvidos no acidente E que ocorreram em alguma das seguintes operadoras: “Autopista Regis Bittencourt”, “Autopista Litoral Sul”, “Via Sul”.
4.4.1 Resumo de informações
No tidyverse, as funções summarise() e group_by() são amplamente utilizadas para resumir informações e realizar cálculos agregados em conjuntos de dados. Elas desempenham um papel crucial na análise exploratória e na obtenção de insights significativos a partir dos dados. Vamos explorar como essas funções funcionam e como usá-las para resumir informações de maneira eficaz.
4.4.1.1 Função summarise()
A função summarise() é utilizada para calcular estatísticas resumidas para uma coluna ou um conjunto de colunas. Ela permite calcular médias, somas, desvios padrão, mínimos, máximos e outras estatísticas relevantes.
Estamos interessados em uma tabela descritiva para a variável levemente_feridos.
tabela <- car_crash %>%
summarise(n = n(),
f_r = n()/nrow(car_crash),
f_per = n()/nrow(car_crash) * 100,
media = mean(levemente_feridos, na.rm = T),
Q1 = quantile(levemente_feridos, 0.25, type = 5, na.rm = T),
Q2 = quantile(levemente_feridos, 0.5, type = 5, na.rm = T),
Q3 = quantile(levemente_feridos, 0.75, type = 5, na.rm = T),
var = var(levemente_feridos, na.rm = T),
sd = sd(levemente_feridos, na.rm = T),
min = min(levemente_feridos, na.rm = T),
max = max(levemente_feridos, na.rm = T)) 4.4.1.2 Agrupamento de dados
A função group_by() é usada para agrupar o conjunto de dados por uma ou mais colunas. Isso cria um contexto em que a função summarise() pode calcular estatísticas específicas para cada grupo.
Estamos interessados em uma tabela descritiva para a variável levemente_feridos por tipo_de_ocorrencia.
tabela <- car_crash %>%
filter(tipo_de_ocorrencia %in% c("sem vítima", "com vítima"))%>%
group_by(tipo_de_ocorrencia) %>%
summarise(n = n(),
f_r = n()/nrow(car_crash),
f_per = n()/nrow(car_crash) * 100,
media = mean(levemente_feridos, na.rm = T),
Q1 = quantile(levemente_feridos, 0.25, type = 5, na.rm = T),
Q2 = quantile(levemente_feridos, 0.5, type = 5, na.rm = T),
Q3 = quantile(levemente_feridos, 0.75, type = 5, na.rm = T),
var = var(levemente_feridos, na.rm = T),
sd = sd(levemente_feridos, na.rm = T),
min = min(levemente_feridos, na.rm = T),
max = max(levemente_feridos, na.rm = T)) 4.5 Exercício
- Utilizando o banco de dados
starwarsfaça o que se pede:
Qual é o número total de espécies únicas presentes? Qual a frequência de indivíduos por espécie?
Calcule a altura média de personagens masculinos e femininos.
Qual é a média de idade dos personagens de cada espécie para personagens masculinos?
Para cada espécie presente na base de dados, identifique o personagem mais velho e sua idade correspondente.
4.6 Manipulação de Data no R
A transformação de strings em datas e a manipulação de datas são tarefas comuns em análise de dados. No R, existem várias funções e pacotes disponíveis para facilitar essas operações. Vamos explorar como realizar essas tarefas usando as funcionalidades básicas do R.
4.6.1 Transformando Strings em Datas
Para transformar strings em datas, podemos utilizar a função as.Date(). Por exemplo:
# String representando uma data
data_string <- "2023-08-21"
# Transformando a string em data
data <- as.Date(data_string)
# Exibindo a data
print(data)[1] "2023-08-21"Também podemos especificar o formato da string de data usando o argumento format. Por exemplo:
4.6.2 Manipulação de Datas
Após transformar strings em datas, podemos realizar várias operações de manipulação de datas. Algumas das operações mais comuns incluem:
- Adição e subtração de dias, semanas, meses ou anos:
data <- as.Date("2023-08-21")
data2 <- data + 7 # Adicionando 7 dias
data3 <- data - 1 # Subtraindo 1 dia- Comparação de datas:
data1 <- as.Date("2023-08-21")
data2 <- as.Date("2023-08-15")
data1 > data2 # Verifica se data1 é posterior a data2[1] TRUE- Formatação de datas para strings:
- Extração de componentes de data (ano, mês, dia):
- Cálculo de diferenças entre datas:
4.6.3 Lubridate: Facilitando a Manipulação de Datas no R
Lidar com datas no R pode ser uma tarefa desafiadora, especialmente quando se precisa realizar operações complexas ou extrair informações específicas das datas. O pacote lubridate foi desenvolvido para simplificar a manipulação de datas, tornando as tarefas relacionadas a datas mais fáceis e intuitivas. Vamos explorar algumas das principais funcionalidades do lubridate em mais detalhes, com exemplos práticos:
4.6.3.1 Instalação e Carregamento do Lubridate
Antes de usar o lubridate, é necessário instalá-lo e carregá-lo no R. Para isso, utilize o comando install.packages("lubridate") para a instalação e library(lubridate) para o carregamento do pacote. Essas etapas devem ser executadas apenas uma vez.
4.6.3.2 Criando Datas
O lubridate torna a criação de datas simples e flexível. Podemos criar datas usando diferentes funções, dependendo do formato dos seus dados. Além da já mencionada ymd() para datas no formato “ano-mês-dia,” também podemos utilizar:
Essas funções ajudam a evitar confusões em relação ao formato das datas, tornando o processo de entrada de dados mais seguro. Veja um exemplo:
4.6.3.3 Operações com Datas
Operações com datas, como adição e subtração de dias, semanas, meses ou anos, são realizadas de forma mais clara e intuitiva no lubridate. O pacote fornece funções específicas para isso, como days(), weeks(), months(), e years(). Isso permite que executemos operações como:
data <- ymd("2023-08-21")
data_nova <- data + days(7) # Adiciona 7 dias
data_anterior <- data - months(2) # Subtrai 2 meses
print(data_nova)[1] "2023-08-28"print(data_anterior)[1] "2023-06-21"Essa sintaxe simplificada torna as operações com datas mais legíveis e menos propensas a erros.
4.6.3.4 Extraindo Informações de Datas
O lubridate permite extrair facilmente informações de datas. Com funções como year(), month(), e day(), você pode obter o ano, mês ou dia de uma data específica. Além disso, é possível extrair informações mais detalhadas, como hora, minuto, e segundo, caso necessário. Isso é particularmente útil ao lidar com séries temporais ou análises de eventos temporais específicos. Veja exemplos:
4.6.3.5 Funções de Resumo de Datas
O lubridate oferece funções que auxiliam na análise e resumo de datas. Podemos calcular a diferença entre duas datas com facilidade, obtendo o resultado em dias, semanas, meses ou anos. Isso é útil em cenários em que é preciso medir a duração entre eventos ou calcular intervalos de tempo:
data1 <- ymd("2023-08-21")
data2 <- ymd("2023-08-15")
diferenca_em_dias <- as.numeric(data2 - data1)
diferenca_em_semanas <- as.numeric(weeks(data2 - data1))
print(diferenca_em_dias)[1] -6print(diferenca_em_semanas)[1] -36288004.6.3.6 Lidar com Fusos Horários
Para situações que envolvem fusos horários, o lubridate facilita a manipulação, permitindo a converção de datas entre fusos e calcule diferenças de tempo em fusos diferentes. Isso é especialmente valioso em análises que abrangem regiões geográficas distintas ou quando é necessário considerar fusos horários em análises de eventos globais.
- Converter uma Data para um Fuso Horário Específico:
Imagine que temos uma data em um fuso horário específico e desejamos convertê-la para outro fuso horário. O lubridate facilita essa tarefa usando a função with_tz(). Veja um exemplo:
# Data original no fuso horário de Nova Iorque
data_ny <- ymd_hms("2023-08-21 12:00:00", tz = "America/New_York")
# Converter para o fuso horário de Londres
data_london <- with_tz(data_ny, tz = "Europe/London")
print(data_ny)[1] "2023-08-21 12:00:00 EDT"print(data_london)[1] "2023-08-21 17:00:00 BST"Neste exemplo, convertemos uma data de Nova Iorque para Londres.
- Calcular a Diferença de Tempo entre Datas em Fusos Horários Diferentes:
Calcular a diferença de tempo entre duas datas em fusos horários diferentes pode ser útil para determinar a sincronização de eventos em locais geograficamente distintos. O lubridate permite isso com facilidade:
# Duas datas em fusos horários diferentes
data_ny <- ymd_hms("2023-08-21 12:00:00", tz = "America/New_York")
data_london <- ymd_hms("2023-08-21 17:00:00", tz = "Europe/London")
# Calcular a diferença de tempo em horas
diferenca_horas <- as.numeric(data_london - data_ny)
print(diferenca_horas)[1] 0- Trabalhar com Fusos Horários em Data Frames:
Em muitos casos, você pode ter um conjunto de dados com datas em diferentes fusos horários. O lubridate permite a manipulação desses dados em um Data Frame de forma eficiente. Suponha que temos um Data Frame chamado dados com datas em diferentes fusos horários:
dados <- data.frame(
nome = c("Evento 1", "Evento 2"),
data = c(
ymd_hms("2023-08-21 12:00:00", tz = "America/New_York"),
ymd_hms("2023-08-21 17:00:00", tz = "Europe/London")
)
)
# Converter todas as datas para um fuso horário comum, por exemplo, UTC
dados$data_utc <- with_tz(dados$data, tz = "UTC")
print(dados) nome data data_utc
1 Evento 1 2023-08-21 12:00:00 2023-08-21 16:00:00
2 Evento 2 2023-08-21 12:00:00 2023-08-21 16:00:00Neste exemplo, convertemos todas as datas no Data Frame para o fuso horário UTC, criando uma nova coluna chamada data_utc.
Lidar com fusos horários em análises de dados é fundamental para garantir que as informações temporais sejam precisas e consistentes, especialmente em cenários globais ou quando eventos ocorrem em locais diferentes ao redor do mundo. O pacote lubridate no R simplifica significativamente essa tarefa, tornando a manipulação de datas com fusos horários uma tarefa mais clara e eficiente.
4.7 Exercícios
Utilizando o banco de dados
car_crashformate a colunadataem uma data (dd-mm-yyyy);Utilizando o banco de dados
car_crashformate a colunahorariopara o horário do acidente (hh:mm:ss)Qual o mês com maior quantidade de acidentes?
Qual ano ocorreram mais acidentes?
Qual horário acontecem menos acidentes?
Qual a média, desvio padrão, mediana, Q1 e Q3 para a quantidade de indivíduos classificados como levemente feridos por mês/ano?
Quantos acidentes com vítimas fatais aconteceram, por mês/ano, em mediana entre as 6:00am e 11:59am.
4.8 Junção de dados
É raro que uma análise de dados envolva apenas uma única fonte de dados. Normalmente, você possui vários data.frames e precisa uni-los para realizar as análises que lhe interessam.
4.8.1 Dados
Para a aula de hoje, utilizaremos o pacote nycflights13, o qual contém dados relacionados a voos na cidade de Nova York.
4.8.2 Chaves Primárias e Chaves Estrangeiras
Para compreender os principais tipos de junções de banco de dados, é fundamental entender como duas tabelas podem ser conectadas por meio de um par de chaves, dentro de cada tabela. Vamos estudar brevemente sobre os dois tipos principais de chaves, para isso, vamos utilizar os conjuntos de dados do pacote nycflights13. Esse pacote apresenta cinco tabelas com informações distintas acerca de vôos em New York.
4.8.2.1 Chaves primárias e estrangeiras
Toda junção envolve um par de chaves: uma chave primária e uma chave estrangeira. Uma chave primária é uma variável ou conjunto de variáveis que identifica cada observação de forma única. Quando mais de uma variável é necessária, a chave é chamada de chave composta. Por exemplo, no nycfights13:
- A tabela
airlinesregistra dois dados sobre cada companhia aérea: seu código de operadora e seu nome completo. Você pode identificar uma companhia aérea pelo seu código de operadora de duas letras, tornando o código de operadora (carrier) a chave primária (primary key).
Loading required package: nycflights13airlines# A tibble: 16 × 2
carrier name
<chr> <chr>
1 9E Endeavor Air Inc.
2 AA American Airlines Inc.
3 AS Alaska Airlines Inc.
4 B6 JetBlue Airways
5 DL Delta Air Lines Inc.
6 EV ExpressJet Airlines Inc.
7 F9 Frontier Airlines Inc.
8 FL AirTran Airways Corporation
9 HA Hawaiian Airlines Inc.
10 MQ Envoy Air
11 OO SkyWest Airlines Inc.
12 UA United Air Lines Inc.
13 US US Airways Inc.
14 VX Virgin America
15 WN Southwest Airlines Co.
16 YV Mesa Airlines Inc. - A tabela
airports, por sua vez, registra dados sobre cada aeroporto. Podemos identificar cada aeroporto pelo seu código de aeroporto de três letras, tornando o códigoFAAa chave primária.
airports# A tibble: 1,458 × 8
faa name lat lon alt tz dst tzone
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <chr> <chr>
1 04G Lansdowne Airport 41.1 -80.6 1044 -5 A America/…
2 06A Moton Field Municipal Airport 32.5 -85.7 264 -6 A America/…
3 06C Schaumburg Regional 42.0 -88.1 801 -6 A America/…
4 06N Randall Airport 41.4 -74.4 523 -5 A America/…
5 09J Jekyll Island Airport 31.1 -81.4 11 -5 A America/…
6 0A9 Elizabethton Municipal Airport 36.4 -82.2 1593 -5 A America/…
7 0G6 Williams County Airport 41.5 -84.5 730 -5 A America/…
8 0G7 Finger Lakes Regional Airport 42.9 -76.8 492 -5 A America/…
9 0P2 Shoestring Aviation Airfield 39.8 -76.6 1000 -5 U America/…
10 0S9 Jefferson County Intl 48.1 -123. 108 -8 A America/…
# ℹ 1,448 more rows- A tabela
planesregistra dados sobre cada aeronave. Podemos identificar uma aeronave pelo seu número de cauda (tailnum), tornando o número de cauda a chave primária.
planes# A tibble: 3,322 × 9
tailnum year type manufacturer model engines seats speed engine
<chr> <int> <chr> <chr> <chr> <int> <int> <int> <chr>
1 N10156 2004 Fixed wing multi… EMBRAER EMB-… 2 55 NA Turbo…
2 N102UW 1998 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
3 N103US 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
4 N104UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
5 N10575 2002 Fixed wing multi… EMBRAER EMB-… 2 55 NA Turbo…
6 N105UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
7 N107US 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
8 N108UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
9 N109UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
10 N110UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
# ℹ 3,312 more rows- A tabela
weatherregistra dados sobre o clima nos aeroportos de origem. Você pode identificar cada observação pela combinação de localização e horário, tornando a origem (origin) e o horário (time_hour) a chave primária composta.
weather# A tibble: 26,115 × 15
origin year month day hour temp dewp humid wind_dir wind_speed
<chr> <int> <int> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl>
1 EWR 2013 1 1 1 39.0 26.1 59.4 270 10.4
2 EWR 2013 1 1 2 39.0 27.0 61.6 250 8.06
3 EWR 2013 1 1 3 39.0 28.0 64.4 240 11.5
4 EWR 2013 1 1 4 39.9 28.0 62.2 250 12.7
5 EWR 2013 1 1 5 39.0 28.0 64.4 260 12.7
6 EWR 2013 1 1 6 37.9 28.0 67.2 240 11.5
7 EWR 2013 1 1 7 39.0 28.0 64.4 240 15.0
8 EWR 2013 1 1 8 39.9 28.0 62.2 250 10.4
9 EWR 2013 1 1 9 39.9 28.0 62.2 260 15.0
10 EWR 2013 1 1 10 41 28.0 59.6 260 13.8
# ℹ 26,105 more rows
# ℹ 5 more variables: wind_gust <dbl>, precip <dbl>, pressure <dbl>,
# visib <dbl>, time_hour <dttm>Uma chave estrangeira é uma variável (ou conjunto de variáveis) que corresponde a uma chave primária em outra tabela. Por exemplo:
-
flights$tailnumé uma chave estrangeira que corresponde à chave primáriaplanes$tailnum. -
flights$carrieré uma chave estrangeira que corresponde à chave primáriaairlines$carrier.
Podemos ver como cada banco de dados está relacionado com os demais na Figura abaixo.
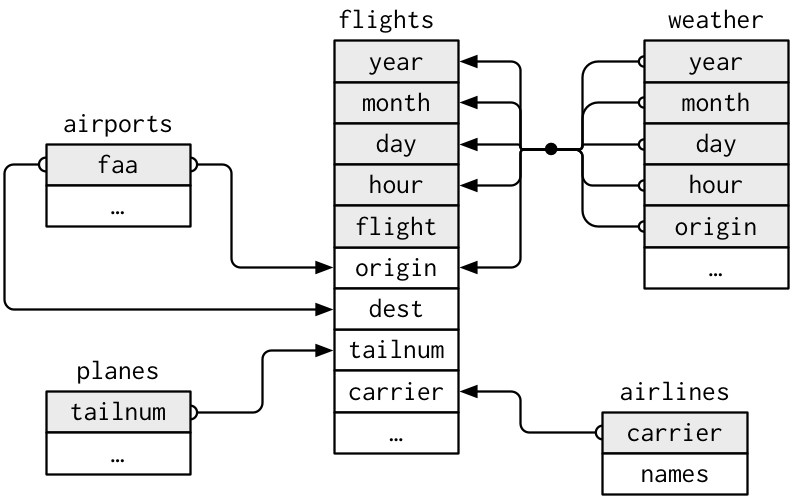
A Tabela “flights” está vinculada à tabela “planes” por meio de uma variável única, “tailnum”.
A Tabela “flights” está vinculada à tabela “airlines” por meio de uma variável única, “carrier”.
A Tabela “flights” está vinculada à tabela “airports” de duas maneiras: por meio das variáveis “origin” e “dest”.
A Tabela “flights” está vinculada à tabela “weather” por meio das variáveis “origin” (localização), “year”, “month”, “day” e “hour”.
Note que as chaves primárias e estrangeiras têm quase sempre os mesmos nomes, o que, como veremos em breve, tornará sua vida de junção muito mais fácil. Também vale a pena observar a relação oposta: quase todos os nomes de variáveis usados em várias tabelas têm o mesmo significado em cada lugar. Há apenas uma exceção: o ano (year) significa o ano de partida nos voos (flights) e o ano de fabricação nas aeronaves (planes).
4.8.2.2 Verificação de Chaves Primárias
Agora que identificamos as chaves primárias em cada tabela, é uma boa prática verificar se elas realmente identificam de forma única cada observação. Uma maneira de fazer isso é contar as chaves primárias e procurar entradas em que n() seja maior que um.
# A tibble: 0 × 2
# ℹ 2 variables: tailnum <chr>, n <int># A tibble: 0 × 3
# ℹ 3 variables: time_hour <dttm>, origin <chr>, n <int>Além de termos chave primária única, é importante que não haja valores faltantes, se um valor estiver ausente, ele não poderá identificar uma observação.
# A tibble: 0 × 9
# ℹ 9 variables: tailnum <chr>, year <int>, type <chr>, manufacturer <chr>,
# model <chr>, engines <int>, seats <int>, speed <int>, engine <chr># A tibble: 0 × 15
# ℹ 15 variables: origin <chr>, year <int>, month <int>, day <int>, hour <int>,
# temp <dbl>, dewp <dbl>, humid <dbl>, wind_dir <dbl>, wind_speed <dbl>,
# wind_gust <dbl>, precip <dbl>, pressure <dbl>, visib <dbl>,
# time_hour <dttm>4.8.3 Combinando dados
Bom, agora que compreendemos a importância de chaves vamos agora introdur dois tipos importantes de junções:
-
Junções mutacionais, que adicionam novas variáveis a um conjunto de dados a partir de observações correspondentes em outro banco de dados. São elas:
-
inner_join; -
full_join; -
left_join; -
right_join.
-
-
Junções de filtragem, que filtram observações de um quadro de dados com base em se elas correspondem ou não a uma observação em outro banco de dados.
4.8.4 Junções Mutacionais
Uma junção mutacional (mutating join) permite combinar variáveis de dois conjuntos de dados: primeiro, ele corresponde às observações através de suas chaves e, em seguida, copia as variáveis de um conjunto de dados para o outro. Assim como a função mutate(), as funções de join adicionam variáveis à direita, portanto, se o seu conjunto de dados tiver muitas variáveis, as novas variáveis não serão imediatamente visíveis. Para facilitar a compreensão dos exemplos a seguir, criaremos um conjunto de dados mais suscinto com apenas seis variáveis, e apenas com vôos com distância superior à 1000km:
flights2 <- flights %>%
filter(distance > 2000) %>%
select(year, time_hour, origin, dest, tailnum, carrier)
flights2# A tibble: 51,695 × 6
year time_hour origin dest tailnum carrier
<int> <dttm> <chr> <chr> <chr> <chr>
1 2013 2013-01-01 06:00:00 JFK LAX N29129 UA
2 2013 2013-01-01 06:00:00 EWR SFO N53441 UA
3 2013 2013-01-01 06:00:00 EWR LAS N76515 UA
4 2013 2013-01-01 06:00:00 JFK SFO N532UA UA
5 2013 2013-01-01 06:00:00 EWR PHX N807AW US
6 2013 2013-01-01 06:00:00 JFK PHX N535UW US
7 2013 2013-01-01 06:00:00 EWR LAX N33289 UA
8 2013 2013-01-01 06:00:00 EWR SNA N38727 UA
9 2013 2013-01-01 06:00:00 JFK LAS N558JB B6
10 2013 2013-01-01 07:00:00 JFK SFO N705TW DL
# ℹ 51,685 more rows4.8.4.1 Left Join
O left join retorna todas as linhas do primeiro conjunto de dados (tabela à esquerda) e as linhas correspondentes do segundo conjunto de dados (tabela à direita), se houver correspondência. Se não houver correspondência na tabela à direita, os valores serão preenchidos com NA (valores ausentes).

Suponha que gostariamos de adicionar o nome completo da companhia aerea no nosso banco de dados. Para isso, precisamos combinar as informações de flights2 com airlines.
Note que, por definição, a função buscou a chave primária como carrier. Nesse caso, como temos apenas uma chave, é viável fazermos isso. Contudo, é uma boa prática definirmos qual a chave que gostaríamos de combinar os bancos de dados.
4.8.4.2 Right Join
O right_join retorna apenas as linhas do primeiro conjunto de dados (tabela à esquerda) se houver correspondência com o segundo conjunto de dados (tabela à direita). Se não houver correspondência na tabela à esquerda, os valores serão preenchidos com NA (valores ausentes).

Suponha que, temos interesse em buscar informações acerca dos dos vôos realizados pelos aviões em flights2. Para isso, basta unirmos as tabelas planes com flights2.
planes_flights = flights2 %>%
right_join(planes, by = "tailnum")4.8.4.3 Inner Join
O inner join retorna apenas as linhas que têm correspondências em ambos os conjuntos de dados. Ou seja, ele preserva apenas as observações com chaves correspondentes em ambas as tabelas.
 Suponha que, temos interesse em buscar informações acerca dos aeroportos de origem realizados pelos aviões em
Suponha que, temos interesse em buscar informações acerca dos aeroportos de origem realizados pelos aviões em flights2. Porém, apenas temos interesse em informações que aparecem em ambos bancos. Para isso, basta unirmos as tabelas flights2 com airports.
origin_flights = flights2 %>%
inner_join(airports, by = c("origin"= "faa"))
origin_flights = flights2 %>%
inner_join(airports, join_by(origin == faa))4.8.4.4 Full Join
O full_join retorna todas as linhas de ambos os conjuntos de dados (tabelas à esquerda e à direita). Ele preenche com NA aqueles valores que não têm correspondência em uma das tabelas.

Suponha que, temos interesse em buscar informações acerca dos aeroportos de destino realizados pelos aviões em flights2. Porém, apenas temos interesse em todas informações que aparecem em ambos bancos. Para isso, basta unirmos as tabelas flights2 com airports.
4.8.5 Junções de Filtragem
Como o próprio nome sugere, a ação principal de uma junção de filtragem é filtrar as linhas. Existem dois tipos: semi-junções e anti-junções. Semi-junções mantêm todas as linhas em x que têm uma correspondência em y. Por exemplo, poderíamos usar uma semi-junção para filtrar o conjunto de dados de aeroportos (airports) para mostrar apenas os aeroportos de origem:
# A tibble: 2 × 8
faa name lat lon alt tz dst tzone
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <chr> <chr>
1 EWR Newark Liberty Intl 40.7 -74.2 18 -5 A America/New_York
2 JFK John F Kennedy Intl 40.6 -73.8 13 -5 A America/New_YorkAnti-junções são o oposto: elas retornam todas as linhas em x que não têm correspondência em y. São úteis para encontrar valores ausentes que são implícitos nos dados. Valores implicitamente ausentes não aparecem como NAs, mas sim existem apenas como uma ausência. Por exemplo, podemos encontrar linhas ausentes em aeroportos procurando voos que não tenham um aeroporto de destino correspondente:
4.9 Exercícios
Para vôos com atraso superior a 24 horas em
flights, verifique as condições climáticas emweather. Há algum padrão? Quais os meses do ano em que você encontra os maiores atrasos?Encontre os 20 destinos mais comuns e identifique seu aeroporto. Qual a temperatura média (mensal) em Celcius desses lugares? E a precipiração média, em cm?
Inclua uma coluna com a cia aérea na tabela
planes. Quantas companhias áreas voaram cada avião naquele ano?Inclua a latitude e longitude de cada origem destino na tabela
flights.
4.10 Organização de dados
Compreender a organização de dados é fundamental para análises estatísticas eficazes. Quando trabalhamos com dados em R, é importante seguir as regras que tornam um conjunto de dados tidy (organizado), o que facilita o processamento e a interpretação dos dados. Existem três regras inter-relacionadas que tornam um conjunto de dados tidy:
-
Cada variável é uma coluna; cada coluna é uma variável: Isso significa que cada característica ou medida que você está analisando deve ser representada por uma coluna separada no conjunto de dados.
- Por exemplo, se você estiver trabalhando com dados de pacientes, as variáveis como idade, gênero, altura e peso devem ser colunas separadas.
- Caso esteja trabalhando com dados de economia global, cada linha refere-se à um país, cada coluna refere-se à uma variável (PIB, IDH, etc).
-
Cada observação é uma linha; cada linha é uma observação: Cada linha do conjunto de dados deve representar uma única observação, caso ou instância. Isso garante que os dados estejam organizados de maneira que seja fácil identificar e comparar diferentes casos.
- Por exemplo, cada linha pode representar um paciente individual em um conjunto de dados médicos.
- Caso esteja trabalhando com dados de economia global, cada linha refere-se à um país.
Cada valor é uma célula; cada célula é um único valor: Cada célula no conjunto de dados deve conter um único valor. Isso significa que não deve haver combinações de valores em uma única célula. Cada célula deve conter uma informação única e específica relacionada à variável e à observação correspondente.
Ao seguir essas três regras, você cria um conjunto de dados tidy que é fácil de manipular, visualizar e analisar. Essa organização facilita a utilização de funções como pivot_longer e pivot_wider para remodelar os dados quando necessário a fim de adaptá-los às necessidades de sua análise estatística em R.

4.10.1 Pivotagem
Pivotar, como o próprio nome sugere, é um processo de transformação de um conjunto de dados, no qual as colunas e linhas são reorganizadas de tal forma que os valores que originalmente estavam dispostos em linhas agora são apresentados como colunas, e vice-versa. Esse procedimento é fundamental para preparar e organizar dados para análises estatísticas e visualizações mais eficazes.
Formato Wide (Largo) e Formato Long (Longo)
Em ciência de dados, é comum falarmos em dois formatos principais: o formato wide (largo) e o formato long (longo). Essas representações são especialmente úteis para diferentes tipos de análises e visualizações.
- Formato Wide (Largo): Nesse formato, os dados são organizados de forma que cada variável é representada por uma coluna separada e cada observação (ou instância) ocupa uma única linha. Isso significa que as informações são distribuídas em várias colunas, tornando-o mais adequado para conjuntos de dados com poucas variáveis, onde as informações são bem condensadas.
- Formato Long (Longo): Já no formato long (ou longo), os dados são organizados de maneira que as variáveis estão empilhadas em uma única coluna, enquanto uma coluna adicional é usada para indicar o nome da variável. Cada observação é representada por uma linha separada. Esse formato é ideal quando se trabalha com conjuntos de dados mais complexos, nos quais as informações estão espalhadas em várias categorias ou momentos de tempo, por exemplo.

4.10.1.1 Exercício
Com os dois conjuntos de dados abaixo, defina qual a versão organizada dos dados.
- Conjunto 1:
- Wide:
| Nome | Idade | Peso (kg) | Gênero |
|---|---|---|---|
| Alice | 34 | 52.16 | Feminino |
| Bob | 35 | 72.57 | Masculino |
| Christine | 38 | 56.70 | Feminino |
- Long:
| Nome | Variável | Valor |
|---|---|---|
| Alice | Idade | 34 |
| Alice | Peso (kg) | 52.16 |
| Alice | Gênero | Feminino |
| Bob | Idade | 35 |
| Bob | Peso (kg) | 72.57 |
| Bob | Gênero | Masculino |
| Christine | Idade | 38 |
| Christine | Peso (kg) | 56.70 |
| Christine | Gênero | Feminino |
- Conjunto 2:
- Wide:
| Tamanho da Pedra | Tratamento A - Recuperados | Tratamento A - Falhas | Tratamento B - Recuperados | Tratamento B - Falhas |
|---|---|---|---|---|
| Pequeno | 81 | 6 | 234 | 36 |
| Grande | 192 | 71 | 55 | 25 |
- Long:
| Tamanho da Pedra | Tratamento | Recuperado | Falha |
|---|---|---|---|
| Pequena | A | 81 | 6 |
| Pequena | B | 234 | 36 |
| Grande | A | 192 | 71 |
| Grande | B | 55 | 25 |
4.10.2 Pivotando dados em R
Para aprendermos sobre os tipos de pivot em R, vamos utilizar o banco de dados table1. Esse banco de dados possui dados de casos reportados de Tuberculose e o tamanho da população em dois anos para três países. Esses dados são provenientes dos dados who.
table1# A tibble: 6 × 4
country year cases population
<chr> <dbl> <dbl> <dbl>
1 Afghanistan 1999 745 19987071
2 Afghanistan 2000 2666 20595360
3 Brazil 1999 37737 172006362
4 Brazil 2000 80488 174504898
5 China 1999 212258 1272915272
6 China 2000 213766 1280428583
4.10.2.1 pivot_wider()
A função pivot_wider é usada para transformar um conjunto de dados de um formato longo para um formato largo. Isso é útil quando temos informações em uma única coluna que desejamos espalhar em várias colunas.
- Sintaxe:
pivot_wider(data, names_from, values_from) - data: O conjunto de dados que você deseja transformar. - names_from: A coluna que contém os nomes das variáveis que você deseja espalhar. - values_from: A coluna que contém os valores correspondentes a essas variáveis.
Exemplo: Transformando em dados de table1 em wide.
- Suponha que queremos o número de casos por ano.
table1 %>%
select(country, year, cases) %>%
pivot_wider(names_from = year, values_from = cases)# A tibble: 3 × 3
country `1999` `2000`
<chr> <dbl> <dbl>
1 Afghanistan 745 2666
2 Brazil 37737 80488
3 China 212258 213766
4.10.2.2 pivot_longer
A função pivot_longer é utilizada para transformar um conjunto de dados de um formato largo (wide) para um formato longo (long). Isso é útil quando temos variáveis espalhadas em várias colunas e desejamos organizar esses dados em uma única coluna, tornando-os mais adequados para análises e visualizações. Geralmente, usamos pivot_longer quando temos variáveis empilhadas em diferentes colunas e queremos reunir essas informações em uma única coluna.
-
Sintaxe:
pivot_longer(data, cols, names_to, values_to)-
data: O conjunto de dados que você deseja transformar. -
cols: As colunas que você deseja empilhar no formato longo. -
names_to: O nome da nova coluna que irá conter os nomes das variáveis empilhadas. -
values_to: O nome da nova coluna que irá conter os valores das variáveis empilhadas.
-
Exemplo: Transformando em dados de table1 em long.
- Suponha que queremos os casos e o tamanho da população como uma variável.
table1 %>%
pivot_longer(cols = -c(country, year),
names_to = "variavel",
values_to = "tamanho")# A tibble: 12 × 4
country year variavel tamanho
<chr> <dbl> <chr> <dbl>
1 Afghanistan 1999 cases 745
2 Afghanistan 1999 population 19987071
3 Afghanistan 2000 cases 2666
4 Afghanistan 2000 population 20595360
5 Brazil 1999 cases 37737
6 Brazil 1999 population 172006362
7 Brazil 2000 cases 80488
8 Brazil 2000 population 174504898
9 China 1999 cases 212258
10 China 1999 population 1272915272
11 China 2000 cases 213766
12 China 2000 population 12804285834.10.2.3 Separando observações
A função separate() divide uma única coluna em várias colunas, dividindo-a sempre que um caractere separador aparece. Vamos considerar o exemplo da table3:
table3# A tibble: 6 × 3
country year rate
<chr> <dbl> <chr>
1 Afghanistan 1999 745/19987071
2 Afghanistan 2000 2666/20595360
3 Brazil 1999 37737/172006362
4 Brazil 2000 80488/174504898
5 China 1999 212258/1272915272
6 China 2000 213766/1280428583Note que a coluna rate é na verdade uma coluna onde temos os casos e a população separadas por “/”. Podemos separar essa coluna em duas utilizando a função separate.
Caso tenhamos interesse em uni-las novamente, podemos utilizar a função unite.
4.10.3 Exemplo
Vamos utilizar os dados de notificações de casos provenientes do site do WHO.
TB <- fread("../data/TB.csv.gz")Este conjunto de dados exemplifica uma situação comum na vida real, onde os dados estão desorganizados e não estão em um formato adequado para análises. Ele apresenta colunas redundantes, códigos de variáveis incomuns e uma abundância de valores ausentes. Em suma, está em uma condição “bagunçada” e precisaremos de várias etapas para limpá-lo e organizá-lo de forma apropriada. Assim como o pacote dplyr, o tidyr foi projetado para que cada função tenha uma função específica e bem definida. Isso significa que, em cenários da vida real, você geralmente precisará encadear várias dessas funções em uma sequência lógica para obter os dados em um estado utilizável.
O ponto de partida mais eficaz geralmente é reunir as colunas que não são consideradas variáveis. Vamos examinar o que temos:
Country (país), iso2 e iso3: Essas três colunas parecem redundantes e especificam o país de formas diferentes. Variável redundante.
Year (ano): É claramente uma variável que representa o ano em que os dados foram registrados.
Outras Colunas Não Identificadas: As colunas restantes, como “new_sp_m014”, “new_ep_m014” e “new_ep_f014”, não sabemos o que representam ainda. De acordo com a estrutura dos nomes das colunas, elas provavelmente contêm valores, não são variáveis.
Portanto, nossa primeira tarefa é agrupar todas as colunas, desde “new_sp_m014” até “newrel_f65”, porque ainda não compreendemos completamente o que essas colunas representam. Chamaremos essa variável genérica de “chave”. Além disso, sabemos que as células dessas colunas representam a contagem de casos, então criaremos uma variável chamada “casos” para armazenar esses valores.
É importante observar que há muitos valores ausentes nos dados atuais. Para facilitar a análise inicial, usaremos a função “values_drop_na” para nos concentrarmos apenas nos valores que estão presentes, deixando os valores ausentes de lado temporariamente.
Dessa forma, estaremos prontos para começar o processo de organização e limpeza desses dados desorganizados.
TB1 <- TB %>%
pivot_longer(
cols = -c(1:4),
names_to = "chave",
values_to = "casos",
values_drop_na = TRUE
)
TB1# A tibble: 97,867 × 6
country iso2 iso3 year chave casos
<chr> <chr> <chr> <int> <chr> <int>
1 Afghanistan AF AFG 1997 new_sp_m014 0
2 Afghanistan AF AFG 1997 new_sp_m1524 10
3 Afghanistan AF AFG 1997 new_sp_m2534 6
4 Afghanistan AF AFG 1997 new_sp_m3544 3
5 Afghanistan AF AFG 1997 new_sp_m4554 5
6 Afghanistan AF AFG 1997 new_sp_m5564 2
7 Afghanistan AF AFG 1997 new_sp_m65 0
8 Afghanistan AF AFG 1997 new_sp_f014 5
9 Afghanistan AF AFG 1997 new_sp_f1524 38
10 Afghanistan AF AFG 1997 new_sp_f2534 36
# ℹ 97,857 more rowsPara tentarmos entender a estrutura de chave, vamos contar ela.
# A tibble: 56 × 2
chave n
<chr> <int>
1 new_ep_f014 1029
2 new_ep_f1524 1018
3 new_ep_f2534 1018
4 new_ep_f3544 1018
5 new_ep_f4554 1014
6 new_ep_f5564 1014
7 new_ep_f65 1011
8 new_ep_m014 1035
9 new_ep_m1524 1023
10 new_ep_m2534 1017
# ℹ 46 more rowsSe olharmos o dicionário de variáveis, presente junto aos dados, estamos interessados nos casos, ou seja, nas variáveis descritas por new. Vamos então, filtrar nossos dados para manter apenas essas variáveis.
Além disso, o dicionário das variáveis nos informa o seguinte:
As três primeiras letras de cada coluna indicam se a coluna contém casos novos (new) ou antigos (old) de tuberculose.
-
As letras seguintes descrevem o tipo de tuberculose:
“rel” indica casos de recaída.
“ep” indica casos de tuberculose extrapulmonar.
“sn” indica casos de tuberculose pulmonar que não puderam ser diagnosticados por esfregaço pulmonar (smear negative).
“sp” indica casos de tuberculose pulmonar que puderam ser diagnosticados por esfregaço pulmonar (smear positive).
A sexta letra indica o sexo dos pacientes com tuberculose, sendo “m” para masculino e “f” para feminino.
-
Os números restantes representam os grupos etários. O conjunto de dados agrupa os casos em sete faixas etárias:
“014” = 0 a 14 anos
“1524” = 15 a 24 anos
“2534” = 25 a 34 anos
“3544” = 35 a 44 anos
“4554” = 45 a 54 anos
“5564” = 55 a 64 anos
“65” = 65 anos ou mais
Para tornar o formato dos nomes das colunas mais consistente, é necessário fazer um pequeno ajuste: infelizmente, os nomes estão ligeiramente inconsistentes, pois em vez de “new_rel”, temos “newrel”. Para isso, vamos utilizar a função str_replace(), a ideia básica é simples: substituir os caracteres “newrel” por “new_rel”. Isso tornará todos os nomes das variáveis consistentes.
TB2 <- TB1 %>%
mutate(chave = stringr::str_replace(chave, "newrel", "new_rel"))
TB2# A tibble: 97,867 × 6
country iso2 iso3 year chave casos
<chr> <chr> <chr> <int> <chr> <int>
1 Afghanistan AF AFG 1997 new_sp_m014 0
2 Afghanistan AF AFG 1997 new_sp_m1524 10
3 Afghanistan AF AFG 1997 new_sp_m2534 6
4 Afghanistan AF AFG 1997 new_sp_m3544 3
5 Afghanistan AF AFG 1997 new_sp_m4554 5
6 Afghanistan AF AFG 1997 new_sp_m5564 2
7 Afghanistan AF AFG 1997 new_sp_m65 0
8 Afghanistan AF AFG 1997 new_sp_f014 5
9 Afghanistan AF AFG 1997 new_sp_f1524 38
10 Afghanistan AF AFG 1997 new_sp_f2534 36
# ℹ 97,857 more rowsPodemos separar os valores em cada código usando duas etapas da função separate(). A primeira etapa dividirá os códigos em cada sublinhado (underscore).
# A tibble: 97,867 × 8
country iso2 iso3 year new type sexage casos
<chr> <chr> <chr> <int> <chr> <chr> <chr> <int>
1 Afghanistan AF AFG 1997 new sp m014 0
2 Afghanistan AF AFG 1997 new sp m1524 10
3 Afghanistan AF AFG 1997 new sp m2534 6
4 Afghanistan AF AFG 1997 new sp m3544 3
5 Afghanistan AF AFG 1997 new sp m4554 5
6 Afghanistan AF AFG 1997 new sp m5564 2
7 Afghanistan AF AFG 1997 new sp m65 0
8 Afghanistan AF AFG 1997 new sp f014 5
9 Afghanistan AF AFG 1997 new sp f1524 38
10 Afghanistan AF AFG 1997 new sp f2534 36
# ℹ 97,857 more rowsNesse caso, podemos eliminar a nova coluna, já que ela é constante em todo o conjunto de dados. Além disso, como mencionado anteriormente, as colunas “iso2” e “iso3” são redundantes e podem ser removidas. A eliminação de colunas não essenciais ajuda a simplificar o conjunto de dados e a economizar espaço de armazenamento.
Agora podemos separar o sexo e a idade.
# A tibble: 97,867 × 6
country year type sexo idade casos
<chr> <int> <chr> <chr> <chr> <int>
1 Afghanistan 1997 sp m 014 0
2 Afghanistan 1997 sp m 1524 10
3 Afghanistan 1997 sp m 2534 6
4 Afghanistan 1997 sp m 3544 3
5 Afghanistan 1997 sp m 4554 5
6 Afghanistan 1997 sp m 5564 2
7 Afghanistan 1997 sp m 65 0
8 Afghanistan 1997 sp f 014 5
9 Afghanistan 1997 sp f 1524 38
10 Afghanistan 1997 sp f 2534 36
# ℹ 97,857 more rows4.10.4 Exercícios
- Utilizando os dados de TB5, crie uma tabela em formato wide, com a quantidade de casos por país por ano. Cada ano deve ser chamado “Ano_.
- Utilizando os dados de TB5, crie uma tabela em formato wide, com a quantidade de casos por país, ano, idade e sexo.
- Dica: Utilize o argumento
values_fnda função.
- Dica: Utilize o argumento
- Volte o banco criado em 1 e 2 para o formato
long.
4.11 Strings
No Capítulo 2 vimos como criar a fazer manipulações simples em strings. Agora vamos aprofundar nossos conhecimentos em manipulação de strings. Para trabalharmos com strings em R, podemos utilizar diversos pacotes, como o base, stringr e stringi . Nas aulas introdutórias focamos apenas nas funções do base, agora vamos focar nas funções do stringr. As funções do pacote stringr são, na sua maioria, wrappers das funções implementadas no stringi .
Strings são objetos (ou variáveis) do tipo texto, e são delimitadas por aspas (duplas ou simples).
Caso eu tenha interesse em criar uma string que contenha aspas, podemos cria-la da seguinte maneira:
var_com_aspas <- "Ela disse: 'Eu adoro lasanha.'"
var_com_aspas[1] "Ela disse: 'Eu adoro lasanha.'"str_view(var_com_aspas)[1] │ Ela disse: 'Eu adoro lasanha.'var_com_aspas2 <- 'Ela disse: "Eu adoro lasanha."'
var_com_aspas2[1] "Ela disse: \"Eu adoro lasanha.\""str_view(var_com_aspas2)[1] │ Ela disse: "Eu adoro lasanha."var_com_aspas3 <- "Ela disse: \"Eu adoro lasanha.\""
var_com_aspas3[1] "Ela disse: \"Eu adoro lasanha.\""str_view(var_com_aspas3)[1] │ Ela disse: "Eu adoro lasanha."var_com_aspas4 <- 'Ela disse: \'Eu adoro lasanha.\''
var_com_aspas4[1] "Ela disse: 'Eu adoro lasanha.'"str_view(var_com_aspas4)[1] │ Ela disse: 'Eu adoro lasanha.'4.11.1 Caracteres especiais
Quando estamos trabalhando com textos, frequentemente temos caracteres especiais. Caracteres especiais são caracteres que não são alfanuméricos e muitas vezes têm funções específicas ou significados especiais em linguagens de programação e processamento de texto. Aqui estão alguns exemplos comuns de caracteres especiais:
-
Espaço em Branco: O espaço em branco, muitas vezes representado como ” ” ou “\s” em linguagens de programação, é um caractere especial que denota um espaço vazio entre palavras ou caracteres em uma string.
- Em R, podemos usar espaços em branco em strings de texto da maneira usual. Por exemplo:
texto <- "Isso é um exemplo de texto com espaços em branco."
str_view(texto)[1] │ Isso é um exemplo de texto com espaços em branco.-
Nova Linha (\n): O caractere “\n” é usado para representar uma quebra de linha em uma string. Quando incluído em uma string, ele faz com que o texto subsequente seja exibido em uma nova linha.
- Para criar uma nova linha em uma string, podemos usar “\n”. Isso é útil para criar múltiplas linhas de texto.
texto_multilinhas <- "Primeira linha\nSegunda linha\nTerceira linha"
str_view(texto_multilinhas)[1] │ Primeira linha
│ Segunda linha
│ Terceira linha-
Tabulação (\t): O caractere “\t” representa uma tabulação horizontal. É frequentemente usado para criar recuos ou alinhar o texto em colunas.
- Para adicionar tabulações em uma string, você pode usar “\t”.
texto_tabulado <- "Primeira coluna\tSegunda coluna\tTerceira coluna"
str_view(texto_tabulado)[1] │ Primeira coluna{\t}Segunda coluna{\t}Terceira coluna- Caracteres de Escape (\): O caractere “\” é usado como um caractere de escape em muitas linguagens de programação. Isso significa que ele “escapa” o significado especial de outros caracteres, permitindo que você os inclua em uma string. Por exemplo, “\” é usado para representar uma única barra invertida em vez de um caractere de escape.
texto_com_barras <- "Isso é uma única barra invertida: \\"
str_view(texto_com_barras)[1] │ Isso é uma única barra invertida: \-
Caracteres Unicode: Em linguagens de programação modernas, podemos usar caracteres Unicode em strings para representar uma ampla variedade de caracteres especiais de diferentes idiomas e símbolos.
- Podemos utilizar códigos Unicode para incluir caracteres especiais em uma string em R. Por exemplo, o símbolo do grau (°) pode ser representado pelo código Unicode “\u00B0”.
texto_unicode_grau <- "A temperatura é de 25\u00B0C."
str_view(texto_unicode_grau)[1] │ A temperatura é de 25°C.- O símbolo “\n” (nova linha), pode ser representados usando seus códigos Unicode.
texto_multilinhas_unicode <- "Primeira linha\u000ASegunda linha"
str_view(texto_multilinhas_unicode)[1] │ Primeira linha
│ Segunda linha- Caracteres matemáticos, como o símbolo de somatório (\(\sum\)), podem ser representados com seus códigos Unicode.
simbolo_somatorio <- "O símolo do somatório é: \u2211"
str_view(simbolo_somatorio)[1] │ O símolo do somatório é: ∑- Emojis também podem ser representados por Unicode.
emoji <- "OMG! Também posso usar emoji! \U1F631"
str_view(emoji)[1] │ OMG! Também posso usar emoji! 😱4.11.2 Concatenando strings
Muitas vezes temos interesse em combinar strings, como faziamos antes com a função paste().
df <- data.frame(nome = c("Ana", "Maria", "João", NA),
sobrenome= c("Santos", "Silva", "Souza", NA))
df %>%
mutate(ola = str_c("Boa noite ", nome, " ", sobrenome, "!")) nome sobrenome ola
1 Ana Santos Boa noite Ana Santos!
2 Maria Silva Boa noite Maria Silva!
3 João Souza Boa noite João Souza!
4 <NA> <NA> <NA>Alternativamente, quando temos diversas variáveis que queremos combinar, podemos utilizar a função str_glue.
nome sobrenome mensagem
1 Ana Santos Boa noite Ana Santos!
2 Maria Silva Boa noite Maria Silva!
3 João Souza Boa noite João Souza!
4 <NA> <NA> Boa noite NA NA!Outra opção para a qual utilizamavamos o paste, era para unir todos os elementos de uma string, utilizando o argumento collapse.
Uma alternativa é utilizarmos a função str_flatten.
df$nome %>%
str_flatten(na.rm = TRUE)[1] "AnaMariaJoão"df$nome %>%
str_flatten(na.rm = TRUE, collapse = ", ", last = " e ")[1] "Ana, Maria e João"4.11.3 Separando Strings
Muitas vezes precisamos separar uma string em duas (ou mais). Na aula passada vimos a função separate. Hoje vamos ver a str_split.
4.11.4 Formatação básica
Muitas vezes queremos passar um texto para caixa alta, caixa baixa, título ou até mesmo formato de sentença. Para isso podemos utilizar as funções: str_to_upper(), str_to_lower(), str_to_title() e str_to_sentence() respectivamente.
texto_exemplo = c("caixa baixa", "CAIXA ALTA", "Texto de sentença", "Texto Em Título")
str_to_lower(texto_exemplo)[1] "caixa baixa" "caixa alta" "texto de sentença"
[4] "texto em título" str_to_sentence(texto_exemplo)[1] "Caixa baixa" "Caixa alta" "Texto de sentença"
[4] "Texto em título" str_to_title(texto_exemplo)[1] "Caixa Baixa" "Caixa Alta" "Texto De Sentença"
[4] "Texto Em Título" str_to_upper(texto_exemplo)[1] "CAIXA BAIXA" "CAIXA ALTA" "TEXTO DE SENTENÇA"
[4] "TEXTO EM TÍTULO" Algumas vezes recebemos um texto desformatado, no sentido de conter diversos espaços no meio do texto. E temos interesse em limpar os excessos de espaço. Para isso podemos utilizar as seguintes funções: str_trim() e str_squish()
texto_com_espaços = " Olá, esse texto tem diversos espaços completamente desnecessários. "
str_trim(texto_com_espaços, side = "left")[1] "Olá, esse texto tem diversos espaços completamente desnecessários. "str_trim(texto_com_espaços, side = "right")[1] " Olá, esse texto tem diversos espaços completamente desnecessários."str_trim(texto_com_espaços, side = "both")[1] "Olá, esse texto tem diversos espaços completamente desnecessários."str_squish(texto_com_espaços)[1] "Olá, esse texto tem diversos espaços completamente desnecessários."4.11.5 Comprimento de string
Muitas vezes temos interesse em encontrar textos incorretos em um banco de dados, uma maneira de identificar essas observações é simplesmente por contar a quantidade de caracteres de uma string. Para isso podemos utilizar a função str_length().
df %>%
mutate(comprimento_nome = str_length(nome)) nome sobrenome Nome_Sobrenome comprimento_nome
1 Ana Santos Ana Santos 3
2 Maria Silva Maria Silva 5
3 João Souza João Souza 4
4 <NA> <NA> <NA> NAAlternativamente podemos estar interessados em contar a quantidade de caracteres especificos. Para isso, utilizamos a função str_count().
nome sobrenome Nome_Sobrenome qtd_a
1 Ana Santos Ana Santos 1
2 Maria Silva Maria Silva 2
3 João Souza João Souza 0
4 <NA> <NA> <NA> NAdf %>%
mutate(qtd_vogais = str_count(nome, "[aeiou]")) %>%
mutate(qtd_consoantes = str_count(nome, "[^aeiou]")) nome sobrenome Nome_Sobrenome qtd_vogais qtd_consoantes
1 Ana Santos Ana Santos 1 2
2 Maria Silva Maria Silva 3 2
3 João Souza João Souza 2 2
4 <NA> <NA> <NA> NA NA4.11.6 Substituição de strings
Algumas vezes podemos estar interessados em substituir alguma string por outra. Para isso podemos utilizar a função str_replace().
df %>%
mutate(nome = str_replace(nome, "ã", "a")) nome sobrenome Nome_Sobrenome
1 Ana Santos Ana Santos
2 Maria Silva Maria Silva
3 Joao Souza João Souza
4 <NA> <NA> <NA>Outras vezes queremos simplesmente remover algum caracter. Para isso utilizamos a função str_remove() para remover a primeira instância do caracter ou str_remove_all() para remover todas as instâncias.
df %>%
mutate(nome = str_remove(nome, "[aeiouã]")) nome sobrenome Nome_Sobrenome
1 An Santos Ana Santos
2 Mria Silva Maria Silva
3 Jão Souza João Souza
4 <NA> <NA> <NA>df %>%
mutate(nome = str_remove_all(nome, "[aeiouã]")) nome sobrenome Nome_Sobrenome
1 An Santos Ana Santos
2 Mr Silva Maria Silva
3 J Souza João Souza
4 <NA> <NA> <NA>4.11.7 Expressões Regulares
Expressões regulares, muitas vezes abreviadas como “RegEx” são padrões de texto que descrevem conjuntos de strings. Elas são amplamente utilizadas para realizar operações de busca, correspondência e manipulação de strings em linguagens de programação e ferramentas de processamento de texto, incluindo R. Alguns símbolos e conceitos-chave em expressões regulares:
- Literais: Caracteres literais correspondem a si mesmos. Por exemplo, a regex “abc” corresponderá à sequência “abc” em uma string.
texto <- "O gato é um animal adorável."
padrao <- "gato"
str_detect(texto, padrao)[1] TRUE-
Meta-caracteres: São caracteres com significados especiais em regex. Alguns exemplos incluem:
.(ponto): Corresponde a qualquer caractere, exceto uma nova linha.*: Corresponde a zero ou mais ocorrências do caractere ou grupo anterior.+: Corresponde a uma ou mais ocorrências do caractere ou grupo anterior.?: Corresponde a zero ou uma ocorrência do caractere ou grupo anterior.[]: Define uma classe de caracteres. Por exemplo,[aeiou]corresponde a qualquer vogal.|(barra vertical): Funciona como um “OU” lógico. Por exemplo, “a|b” corresponde a “a” ou “b”.
texto <- c("O rato correu para o buraco.",
"O gato correu para o buraco.",
"O mato.")
padrao <- "(g|r)ato"
str_detect(texto, padrao)[1] TRUE TRUE FALSE-
Âncoras: São usadas para ancorar padrões em posições específicas da string.
^: Corresponde ao início da string.$: Corresponde ao final da string.\b: Corresponde a uma borda de palavra (início ou fim de uma palavra).
texto <- c("Banana", "Ana", "Ananas")
padrao <- "^ana"
str_detect(texto, padrao)[1] FALSE FALSE FALSE## Ignorar case
str_detect(texto, "(?i)ana")[1] TRUE TRUE TRUE## Ignorar case, terminar com ana
str_detect(texto, "(?i)ana$")[1] TRUE TRUE FALSE## Ignorar case, começar com ana
str_detect(texto, "(?i)^ana")[1] FALSE TRUE TRUE## Ignorar case, exatamente ana
str_detect(texto, "(?i)^ana$")[1] FALSE TRUE FALSE-
Grupos: Parênteses
()são usados para agrupar caracteres em subexpressões. Isso é útil para aplicar operadores a um conjunto de caracteres.- Exemplo:
(abc)+corresponde a “abc”, “abcabc”, “abcabcabc”, etc.
- Exemplo:
str_extract(texto, "(na)+")[1] "nana" "na" "nana"-
Quantificadores: Controlam o número de ocorrências de um caractere ou grupo.
{n}: Corresponde exatamente a n ocorrências.{n,}: Corresponde a pelo menos n ocorrências.{n,m}: Corresponde de n a m ocorrências.
texto <- "Os números 123 e 456 são importantes."
padrao <- "\\d{3}"
numeros <- str_extract_all(texto, padrao, simplify = TRUE)
numeros [,1] [,2]
[1,] "123" "456"texto <- "Os números 123, 456 e 78 são importantes."
padrao <- "\\d{2}"
numeros <- str_extract_all(texto, padrao, simplify = TRUE)
numeros [,1] [,2] [,3]
[1,] "12" "45" "78"4.11.8 Exercício
Utilizando os dados disponíveis em words crie RegEx capaz de encontrar palavras que:
Comece com “y”.
Não comece com “y”.
Termine com “x”.
Tenham exatamente três letras.
Tenham sete letras ou mais.
Contenham um par vogal-consoante.
Contenham pelo menos dois pares vogal-consoante consecutivos.
Para cada um dos desafios a seguir, tente resolvê-los usando tanto uma única expressão regular quanto uma combinação de várias chamadas de str_detect():
Encontre todas as palavras que começam ou terminam com “x”.
Encontre todas as palavras que começam com uma vogal e terminam com uma consoante.
Existem palavras que contêm pelo menos uma de cada vogal diferente?
Em `colors()` existem diversos modificadores de cores como light e dark. Crie um banco contendo o nome da cor original e o nome sem o modificador.
4.12 Cheatsheets
Jogo de palavra cruzadas em RegEx.